Data Driven Development of Autonomous Driving at BMW
 |
前言

上圖這是筆者加入小馬智行之前的一個小故事。這不斷的提醒筆者,人工智慧需要有足夠的數據量,並且充分發揮這些數據的潛能,是我們作為人工智慧公司的,一個非常重要的核心競爭力。
數據的作用
- 數據驅動開發:提到數據的作用,我們首先會想到,數據驅動開發,包括感知領域、行為預測領域、決策領域,需要有數據(標注好的數據),來作為我們模型訓練的糧食,和作為系統準確度評測的依據。
- 數據驅動決策:尤其是優先級的決策,作為創業公司我們現在想做的事情,遠遠多於我們的人力,如何把人力用在我們需要優先解決的問題上,不管在行車安全性、乘坐舒適性、車輛的營運等等,每個方面都有更重要的問題,或者次要一點的問題,需要做優先級的決策,透過對於數據的分析和處理,拿出一些有效的決策。
- 展現公司實力:透過對數據的分析,展示出來的結果,是可以展示公司實力的。
- 滿足監管要求:數據的保存、處理、分析,也是為了滿足監管的要求。
數據標注
在講數據驅動開發和決策前,先分享下關於數據標注的一些體會。
- 評價指標
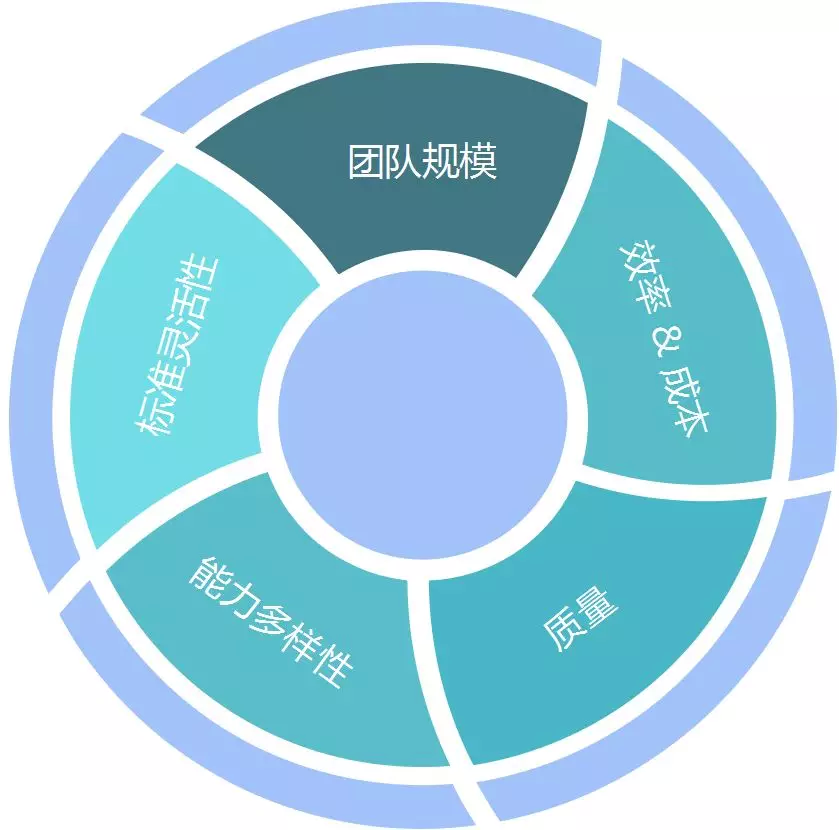
對於數據標注來說,它的評價指標有:
① 團隊規模:只有你有足夠大的團隊,你才能在單位時間內,標注出你所需要的數量的數據。
② 效率和成本:二者間的關係,像是硬幣的正反兩面,效率是指單個人單位時間的產出量,成本是指單位產出的人力、設備、場地開銷。
③ 品質:標注的準確度,比如標注一個雷射點雲裡,障礙物的尺寸、位置、朝向的準確度,又比如預測下一步行為的準確度。
這是大家通常所關注的三個方面,下面再講下,另外兩個很重要的點:
① 能力多樣性:能夠處理各種不同種類的,標注任務的能力,對地圖來說,我們需要標注車道線;對於感知來說,我們需要標交通燈、障礙物,還有行為預測所需要的標注等。
② 標準靈活性:各種長尾場景(如雨點,汽車廢氣等)的處理方式,在不斷的探索和更新,隨之標注的方式,也在不斷的探索和更新,如何保證在這些快速探索,和更新過程中標注團隊直接的高效溝通,不至於出現混亂,這需要花很多精力去做。
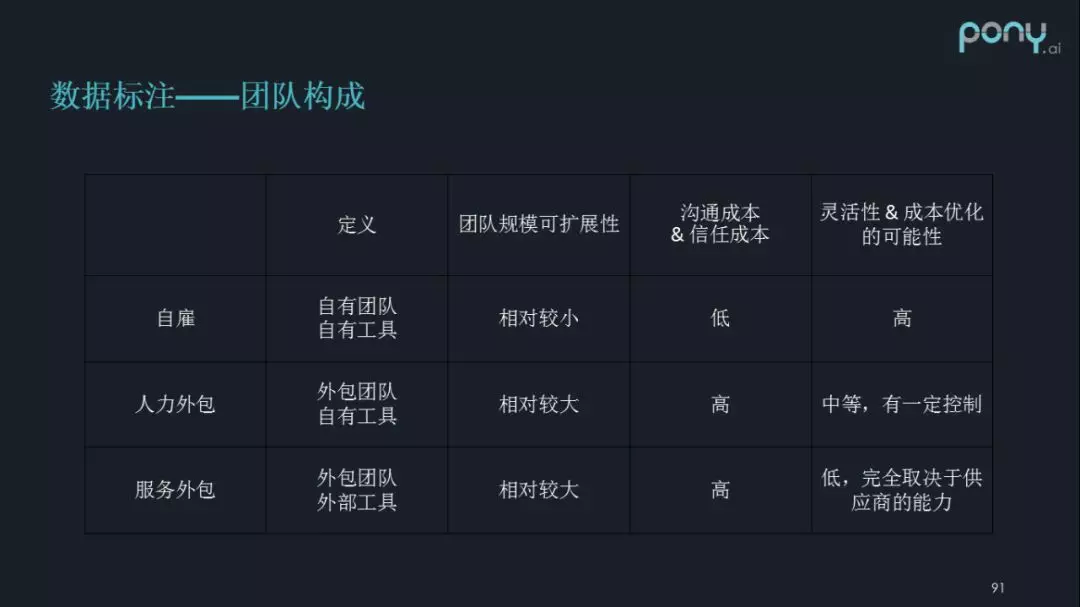
- 團隊構成
如下圖所示:
- 效率提升與成本控制
技術手段:
① 默認障礙物大小:第一幀可以透過一些人機交互的方式,默認障礙物大小。

② 自動追蹤外推:接下來,比如說標注員跳了一幀,到第 3 幀,然後把車新的位置手工找到了,當再跳到第 5 幀的時候,系統就可以透過智慧算法,做到自動的追蹤外,推來找到車在第 5 幀中的新位置。

③ 自動插值:當車在第 1 幀、第 2 幀、第 5 幀的位置,都標出來之後,系統可以做自動插值,自動找到車在第 2 幀,第 4 幀中的位置。
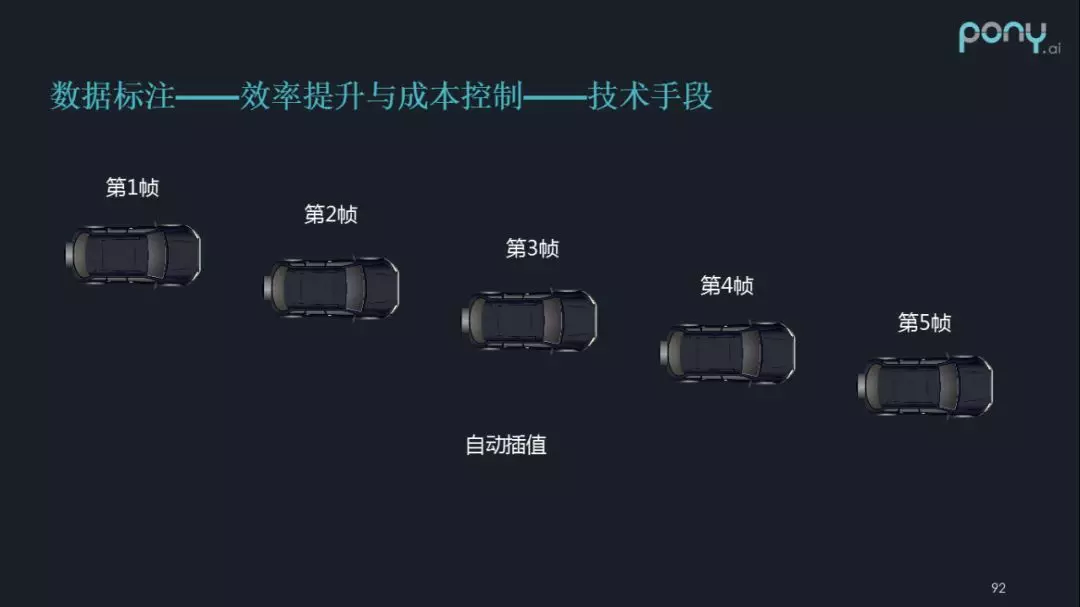
這裡大概看下車的整個標注過程,以及人機交互方面的技巧,透過人工智慧的方法,提高標注員的效率。
相比於車載系統,智慧標注系統所受的限制更少:
① 更多的可用資訊:比如在嘗試智慧標注,某一幀數據的時候,可以參考其後的數據幀裡的資訊;
② 更寬鬆的計算資源和時間限制。
需要注意的問題:
- 對自動化結果的依賴,可能導致標注結果中,產生系統性偏差
- 如何發現和辨識這些系統性偏差
- 不同的自動化功能,產生系統性偏差的幾率和程度,各不相同
非技術手段:
① 薪酬激勵
② 組織結構設計:這裡最主要的是資訊流動的結構,比如:具體的某些場景的某個細節,如何透過標注平台的某些技巧去標注,如何促進這些技巧,在標注團隊內部被高效地總結、傳播。
③ 各工段之間成本平衡:系統化的思考,我們標準的流程分為標注、質檢、複檢等多個工段,透過各工段的配合,達到整體的優化,而不是單純的只優化某個工段。
當然所有的非技術手段,依賴於標注平台,對於標注任務生命週期,與標注團隊架構、績效的管理。
- 系統能力
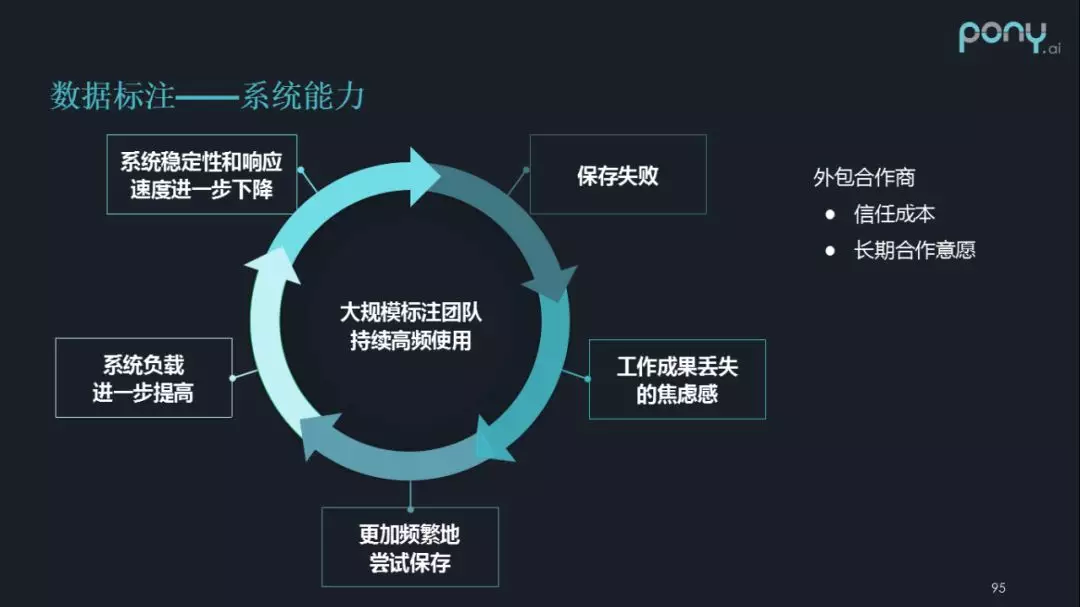
這裡的一個核心目標,是何如保證系統在大規模標注,團隊持續高頻使用的條件下,能保持穩定運行。這裡舉一個因為平台不穩定性產生的焦慮感,進而導致惡性循環的例子:
- 保存失敗:比如標注了 5 分鐘,嘗試保存的時候失敗了。
- 工作成果丟失的焦慮感
- 更加頻繁地嘗試保存
- 系統負載進一步提高
- 系統穩定性和響應速度進一步下降
而且有些時候牽扯到外部合作商時,會進步一加劇一種情況:信任成本升高,降低長期合作意願。
這對我們提出的要求是:
① 不斷優化、提升效率
② 保持穩定、保障效率:最細微的穩定性問題,都可能導致效率下降
③ 良好的工程實踐:
- 與線上系統隔離的完整測試環境,要求能較為準確地重現線上數據規模和數據分布
- 分級發佈流程
- 線上系統監控及應急處理預案
關於提升效率的 Tips:
- 開發:實現效率優化方案
- 測量:在實現方案後,對標注員的操作流程和節奏,進行記錄和準確復現
- 提升:在測量和觀察中,發現可能的效率提升點,然後再循環到第一點。
數據驅動開發
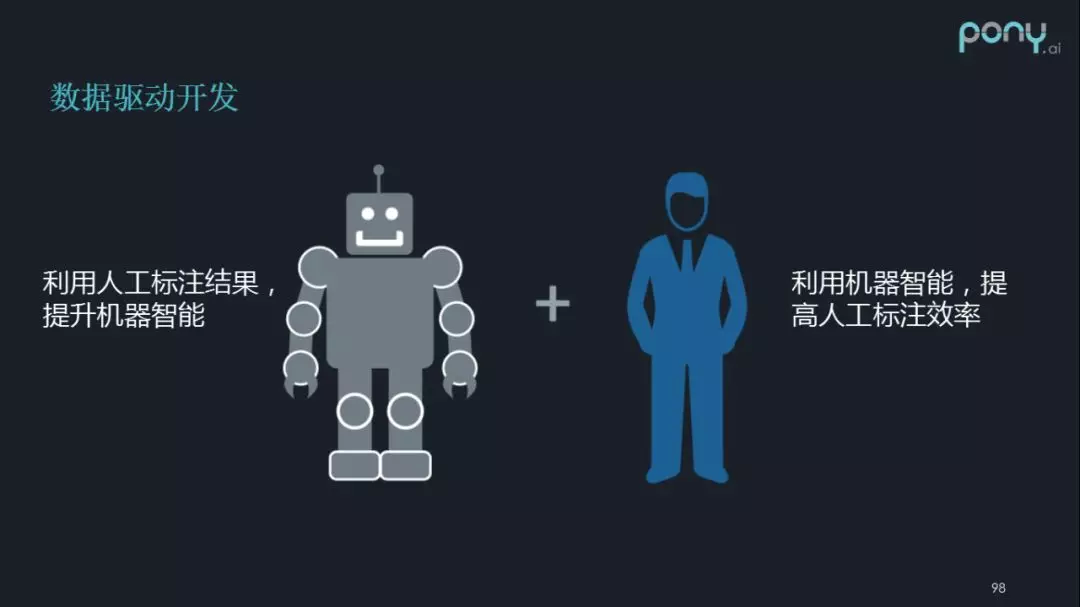
上圖是我們的一個願景:先是利用機器智慧,提高人工標注效率,然後利用人工標注結果,提升機器智慧,最後再反過來利用機器智慧,提高人工標注效率,達到一個交互促進的過程。
- 充分利用海量標注數據
① 分布式訓練和評測系統
② 人工標注的質量是有極限的,這需要我們:
- 對標注數據的進一步處理與修正
- 在設計評測指標時,要考慮到標注數據常見的品質問題。避免設計出的評測指標,對於這些常見品質問題過於敏感。
- 數據索引平台
數據在各個維度上的分布,例如:
- 時段和天氣
- 道路等級
- 障礙物種類
- 住宅、商業區、工業區
當我有了索引平台,可以做的事情有:
① 標注任務篩選:基於分布上不平衡的維度,對路測原始數據的自動化初篩
② 訓練數據選取:按照指定的維度檢索訪問標注數據
③ 評測數據集維護:難度和規模分級
- 路測事件分析
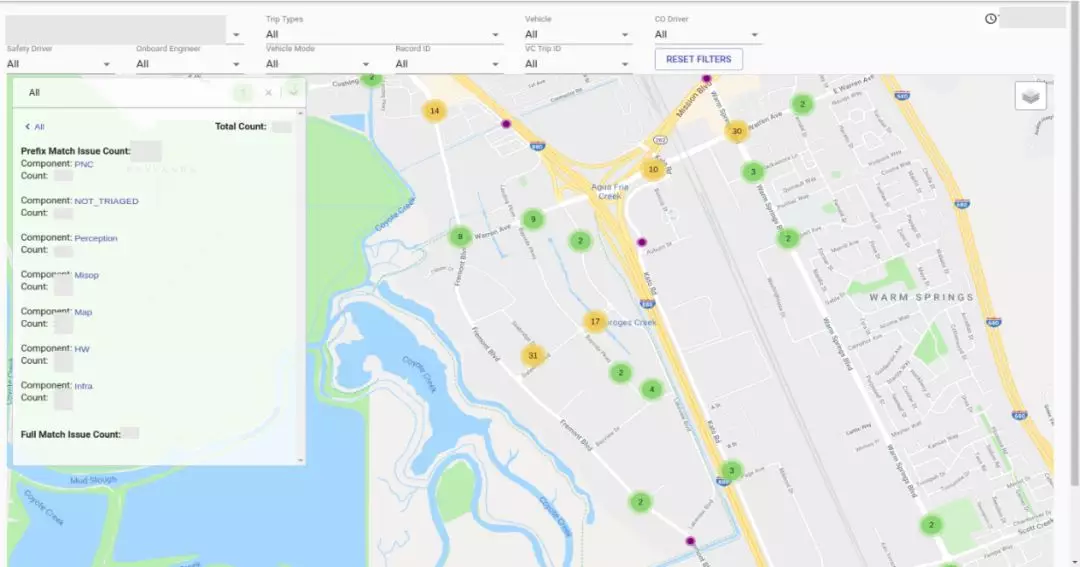
- 問題路段
- 問題模塊
- 問題車輛
- 問題時間段
- 深入分析的工具
- 數據展現方式
- 這裡我們主要面臨的挑戰:
- 準確性:給的數據要可靠、有說服力
- 實時性:每次採集的數據都可以即時更新
- 易用性:從介面上可以直觀的看到關鍵數據
- 這需要我們:① 以用戶為中心,依據關鍵決策流程,不斷迭代與優化② 根據不同受眾和使用場景,提供差異化的視圖
- 營運團隊周會
- 公司高管 C-level
- 團隊 tech lead
- ③ 在每個視圖中,提供最簡潔實用的圖表
- 在默認視圖中,提供剛剛好使用者想要的資訊,不多不少
- 對於每一個數據點,提供進一步深入分析的工具
- 作者介紹宋浩,Pony.ai Tech lead。對岸中國清華大學交叉資訊研究院博士,此前任職於 Facebook 廣告分發策略優化部門。目前在 Pony.ai 負責自動駕駛數據平台與應用的技術研發。本文來自 DataFun 社區原文鏈接:



0 comments:
張貼留言