
這篇報導是所有從事安控行業的人,必須要了解的基本知識 ……

什麼是電腦視覺?你需要了解的關於電腦視覺、實際應用,以及最新趨勢的一切。
什麼是電腦視覺?它是如何運作的?本報導將全面介紹人工智慧 (AI) 的關鍵領域之一 —— 電腦視覺 (CV,Computer Vision)。
什麼是電腦視覺 AI?
電腦視覺 (CV) 是人工智慧 (AI) 的一個領域,它研究幫助電腦理解和解讀數位圖像和影像內容的計算方法。因此,CV 目的在讓電腦能夠看到,並理解來自攝影機或感測器的視覺資料輸入。

電腦視覺的定義
電腦視覺任務目的,在使電腦系統能夠自動觀察、辨識和理解視覺世界,並使用計算方法模擬人類視覺。
人類視覺 vs. 電腦視覺
電腦視覺目的在透過使電腦,能夠有意義地感知視覺刺激,來人工模擬人類視覺。因此,它也被稱為機器感知或機器視覺。
雖然人類(甚至是兒童)可以輕鬆解決「視覺」問題,但視覺運算仍然是電腦科學中,最具挑戰性的領域之一,尤其是由於不斷變化的實體世界的巨大複雜性。

人類的視覺是基於終身學習,結合情境來訓練,如何辨識特定物體,或辨識視覺場景中的人臉或個體。因此,現代人工視覺技術運用機器學習和深度學習方法,來訓練機器辨識視覺場景中的物體、人臉或人物。
因此,電腦視覺系統使用影像處理演算法,使電腦能夠根據攝影機提供的數據來尋找、分類和分析物體,及其周圍環境。
電腦視覺的價值是什麼?
電腦視覺系統可以執行產品檢測、基礎設施監控,或即時分析數千種產品或流程,以檢測缺陷。由於其速度、客觀性、連續性、準確性和可擴展性,電腦視覺系統可以迅速超越人類的能力。
最新的深度學習模型,在現實世界的影像辨識任務(例如臉部辨識、物件偵測和影像分類)中,實現了超越人類層級的準確性和效能。
電腦視覺應用涵蓋各行各業,從安全監控和醫學成像,到製造業、汽車業、農業、建築業、智慧城市、交通運輸等等。隨著人工智慧技術的進步,和變得更加靈活與可擴展性,更多的應用案例變得可能,並且具有經濟可行性。

電腦視覺市場規模
根據 Verified Market Research(2022 年 11 月)對人工智慧視覺市場的分析,2021 年電腦視覺市場中的人工智慧價值為 120 億美元,預計到 2030 年將達到 2,050 億美元。因此,電腦視覺市場在 2023 年至 2030 年期間的複合年成長率高達 37.05%。

建構應用的電腦視覺平台
電腦視覺平台 Viso Suite 協助全球領導者,開發、擴展和營運其 AI 視覺應用。作為全球唯一的端對端 AI 視覺平台,Viso Suite 提供的軟體基礎架構,可顯著加速各行業電腦視覺應用的開發和維護(取得經濟影響研究報告)。
Viso Suite 涵蓋電腦視覺的整個生命週期,從影像標註和模型訓練,到視覺開發、一鍵佈署,以及擴展到數百支攝影機。該平台提供即時效能、分散式邊緣 AI、零信任安全性,和開箱即用的隱私保護 AI 等關鍵功能。
Viso Suite 的可擴展性架構,可協助企業重複使用,和整合現有基礎架構(攝影機、AI 模型等),並將電腦視覺與商業智慧 (BI) 工具(PowerBI、Tableau)和外部資料庫(Google Cloud、AWS、Azure、Oracle 等)連接起來。
電腦視覺 AI 如何運作?
一般來說,電腦視覺的工作原理分為三個基本步驟:
- 從攝影機取得圖像/影像;
- 處理影像;
- 理解圖像。
電腦視覺的實際範例
電腦視覺機器學習需要大量資料,來訓練能夠準確辨識影像的深度學習演算法。例如,要訓練電腦辨識頭盔,需要輸入大量包含不同場景中,佩戴頭盔的人員的頭盔影像,以學習頭盔的特徵。
接下來,可以將訓練好的演算法,應用於新生成的影像(例如監視攝影機的影像),以辨識頭盔。例如,這可用於電腦視覺設備檢查,以減少建築或製造業的事故。

電腦視覺技術的工作原理
為了訓練電腦視覺演算法,最先進的技術利用深度學習(機器學習的一個分支)。現代電腦視覺軟體中的許多高效能方法,都是以卷積神經網路 (CNN)為基礎。
這種分層神經網路使電腦能夠從影像中,學習視覺資料的上下情境。如果有足夠的數據,電腦就能學習如何區分不同的影像。當影像資料輸入模型時,電腦會應用卷積神經網路 (CNN) 來「觀察」資料。
CNN 透過將圖像分解成像素,並賦予像素標籤來訓練特定特徵(即所謂的圖像標註),從而幫助機器學習/深度學習模型理解圖像。人工智慧模型使用這些標籤進行卷積運算,預測其「看到」的內容,並反覆檢查預測的準確性,直到預測符合預期(開始實現)。
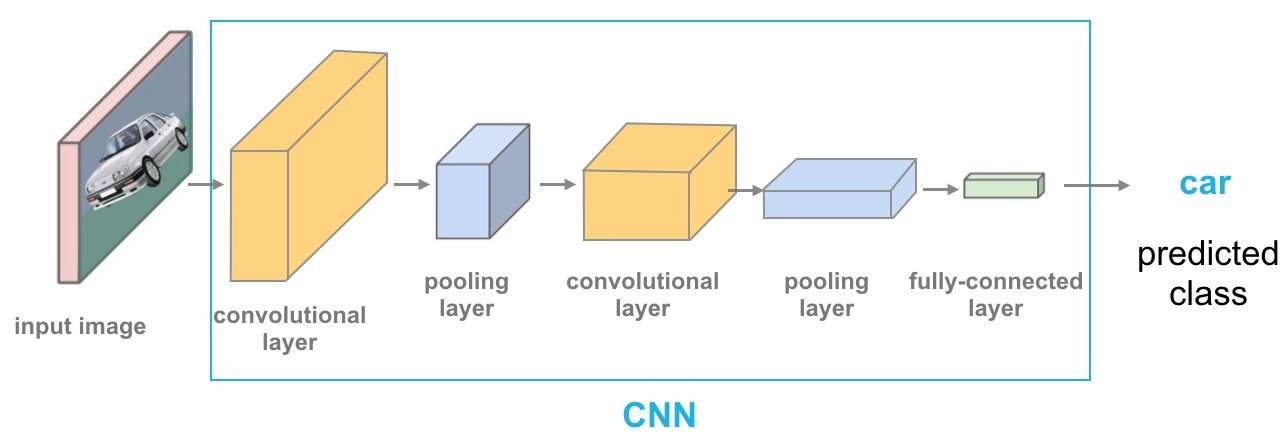
受人腦啟發的視覺運算
因此,電腦視覺的工作原理,是利用學習到的特徵和可信度分數,辨識圖像,或「看到」與人類相似的圖像。因此,神經網路本質上模擬了人類的決策過程,即神經元活化機制,而深度學習則訓練機器,執行人腦自然而然的操作。
深度神經網路特有的分層結構,是人工神經網路 (ANN) 的基礎。每一層都會增強前一層的知識。
電腦視覺 AI 達到人類層面的效能
深度學習任務運算量大且成本高昂,依賴大量的運算資源,需要海量資料集來訓練模型。與傳統的影像處理相比,深度學習演算法使機器能夠自主學習,無需開發人員編程,使其基於預定特徵辨識影像。因此,深度學習方法能夠達到非常高的準確率。
如今,深度學習使機器能夠在影像辨識任務中,達到人類水準的表現。例如,在深度人臉辨識領域,AI 模型的偵測準確率(例如,Google FaceNet 的準確率高達 99.63%),高於人類的準確率(97.53%)。
基於深度學習的視覺運算,在皮膚癌分類方面也達到了人類的水準,其能力水準堪比皮膚科醫生。
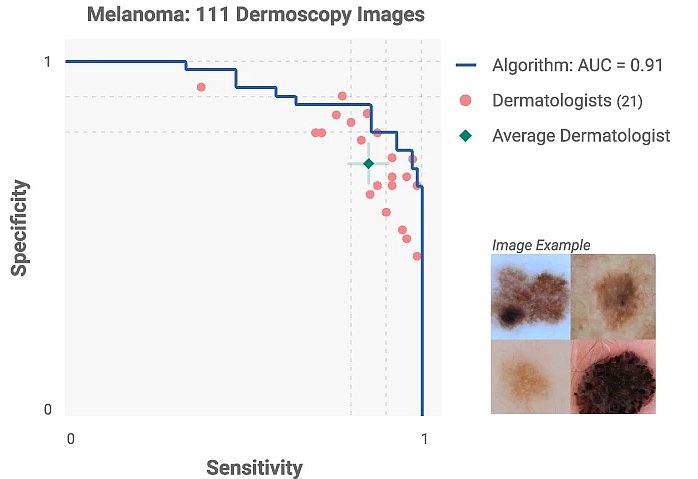 |
| 經過訓練用於疾病分類的神經網路,已與醫生進行了廣泛的基準測試。在相同的分類任務上,它們的表現通常與人類相當。 |
什麼是電腦視覺系統?
現代電腦視覺系統將影像處理,與機器學習和深度學習技術相結合。因此,開發人員將不同的軟體(例如 OpenCV 或 OpenVINO)和 AI 演算法結合,創建一個多步驟的流程,即電腦視覺管線。
電腦視覺系統的組織和設定,因應用和應用案例而異。但是,所有電腦視覺系統都包含相同的典型功能:
步驟 1:影像擷取。攝影機或影像感測器的數位影像,提供圖像資料或影像。從技術上講,任何 2D 或 3D 攝影機或感測器,都可用於提供影像幀。
步驟 2:預處理。攝影機的原始影像輸入,需要進行預處理,以優化後續電腦視覺任務的效能。預處理包括降噪、對比度增強、重新縮放,或影像裁切。
步驟 3:電腦視覺演算法。影像處理演算法,最常見的是深度學習模型(DL 模型),對每個影像或影像幀執行影像辨識、目標偵測、影像分割和影像分類。
步驟 4:自動化邏輯。 AI 演算法的輸出資訊,需要根據應用案例使用條件規則進行處理。此部分基於從電腦視覺任務中,獲得的資訊執行自動化。例如,在自動檢測應用中判斷「通過」或「未通過」,在辨識系統中判斷「吻合」或「不吻合」,以及在保險、安全監控、軍事或醫療辨識應用中,判斷是否需要人工審核。
當今最佳電腦視覺 AI 深度學習模型
在電腦視覺領域,特別是即時目標偵測領域,存在單階段和多階段演算法。
單階段演算法的目的,在實現即時處理和最高的運算效率。最受歡迎的演算法包括 SSD、RetinaNet、YOLOv3、YOLOR、YOLOv5、YOLOv7 和 YOLOv8。
多階段演算法執行多個步驟,並實現最高的準確率,但運算量較大且資源密集。廣泛使用的多階段演算法,包括循環卷積神經網路 (R-CNN),例如 Mask-RCNN、Fast RCNN 和 Faster RCNN。
電腦視覺人工智慧技術發展史
近年來,深度學習技術取得了巨大突破,尤其是在影像辨識和目標偵測領域。
1960 年 - 起源。電腦視覺誕生於 1960 年代,當時電腦科學家試圖利用計算力學,模擬人類的視力。儘管電腦視覺研究已經花了數十年時間,試圖教導機器如何「看」,但當時最先進的機器也只能感知普通物體,難以辨識形狀變化無窮的多種自然物體。
2014 - 深度學習時代。研究人員利用深度學習技術,利用全球最大的影像分類資料集ImageNet 中的 1500 萬張影像訓練電腦,取得了重大突破。在電腦視覺挑戰賽和基準測試中,深度學習展現出壓倒性的優勢,超越了將物體視為形狀和顏色特徵集合的傳統電腦視覺演算法。
2016 - 準即時深度學習。深度學習是一類特殊的機器學習演算法,它透過多層卷積神經網路(CNN),簡化了特徵提取和描述的過程。深度神經網路依賴 ImageNet 的大量資料、現代中央處理器 (CPU) 和圖形處理器 (GPU),推動了電腦視覺的空前發展,並達到了頂尖的效能。尤其是單階段目標偵測器的出現,使得深度學習 AI 視覺的處理速度更快、更有效率。
2020 年代 —— 深度學習的佈署和邊緣 AI。如今,CNN 已成為電腦視覺領域事實上的標準運算框架。隨著更深層、更複雜的網路的開發,CNN 在許多電腦視覺應用中,達到了接近人類的精確度。
優化的輕量級 AI 模型,使得在廉價硬體和行動裝置上,執行電腦視覺任務成為可能。邊緣 AI 硬體,例如深度學習硬體加速器,實現了高效的邊緣推理。
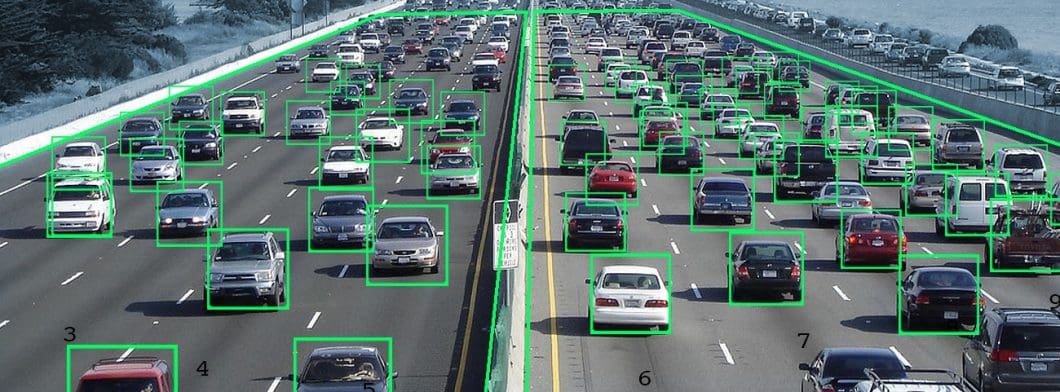
電腦視覺 AI 的當前趨勢和最新技術
最新趨勢將邊緣運算與設備上的機器學習(也稱為邊緣 AI)相結合。將 AI 處理從雲端遷移到邊緣設備,使得在任何地方運行電腦視覺機器學習,並建立可擴展的應用成為可能。
我們看到電腦視覺成本呈下降趨勢,這得益於更高的運算效率、更低的硬體成本,以及新技術的推動。因此,越來越多的 CV 應用已變得可行且經濟可行,進一步加速了其應用。
目前最重要的電腦視覺趨勢包括:
- 即時影像分析
- AI 模型優化與佈署
- 硬體 AI 加速器
- 邊緣電腦視覺
- 現實世界的電腦視覺應用
即時影像分析
傳統的機器視覺系統,通常依賴特殊的攝影機,和高度標準化的設定。相形之下,現代深度學習演算法更加穩健,易於重複使用和重新訓練,並支援跨行業應用的開發。
現代深度學習電腦視覺方法,可以分析常見、廉價的監視攝影機或網路攝影機的影像串流,以執行最先進的人工智慧影像分析。
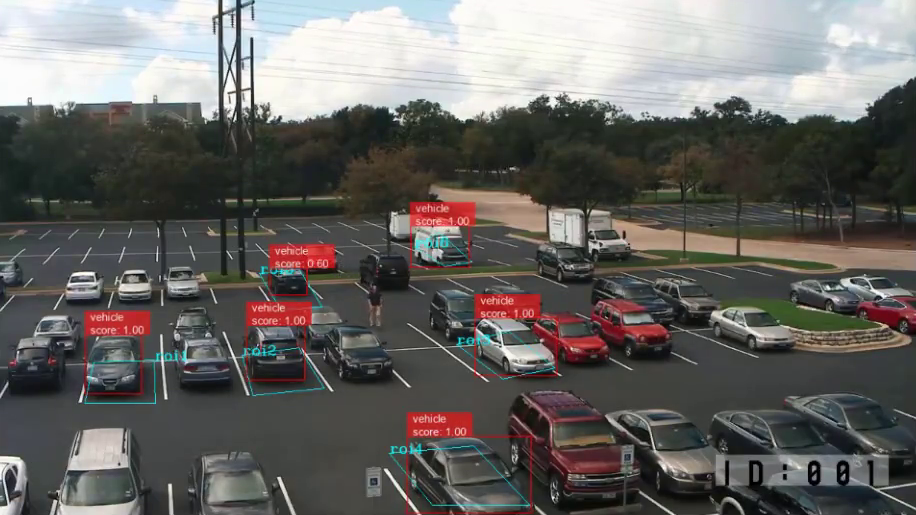
AI 模型優化與佈署
經過十年的深度學習訓練,我們致力於提高演算法的準確性和效能,如今我們已進入深度學習佈署時代。AI 模型最佳化和全新架構,使得大幅縮減機器學習模型規模,並提升運算效率成為可能。這使得運行深度學習電腦視覺成為可能,而無需依賴資料中心昂貴且耗能的 AI 硬體和 GPU。
硬體 AI 加速器
同時,我們正面臨高性能深度學習晶片的蓬勃發展,這些晶片的能源效率越來越高,並且能夠在小型設備和邊緣電腦上運行。目前流行的深度學習 AI 硬體包括邊緣運算設備,例如嵌入式電腦和 SoC 設備,例如 Nvidia Jetson TX2、Intel NUC 或 Google Coral。

用於神經網路的 AI 加速器,可以連接到嵌入式運算系統。最受歡迎的硬體神經網路 AI 加速器,包括英特爾 Myriad X VPU、Google Coral 和英偉達 NVDLA。
邊緣電腦視覺
傳統上,由於運算資源無限可用且易於擴充,電腦視覺和人工智慧通常採用純雲端解決方案。Web 或雲端電腦視覺解決方案,需要將所有圖像或照片上傳到雲端,可以直接上傳,也可以使用電腦視覺 API,例如 AWS Rekognition、Google Vision API、微軟圖像辨識 API(Azure 認知服務)或 Clarifai API。
在關鍵任務案例中,由於技術原因(延遲、頻寬、連接性、備援)或隱私原因(敏感資料、合法性、安全性),或成本過高(即時、大規模、高解析度、瓶頸導致成本飆升),通常無法使用集中式雲端設計進行資料卸載。因此,邊緣運算概念被用來克服雲端的限制;將雲端擴展到多個連接的邊緣設備。
邊緣人工智慧 (Edge AI),也稱為邊緣智慧 (Edge Intelligence) 或裝置端機器學習 (On-device ML),利用邊緣運算和物聯網 (IoT) ,將機器學習從雲端遷移到靠近資料來源(例如攝影機)的邊緣裝置。隨著邊緣產生的大量數據呈指數級成長,人工智慧需要即時分析和理解數據,同時又不損害視覺數據的隱私和安全。
現實世界的電腦視覺應用
因此,邊緣電腦視覺 (CV) 利用雲端和邊緣的優勢,使人工智慧視覺技術具有可擴充性和靈活性,從而支援現實世界應用的實施。設備端電腦視覺無需依賴雲端的資料卸載,和低效的集中式影像處理。
此外,邊緣電腦視覺並不完全依賴網路連接,所需的頻寬和延遲都更低,這在影像分析中尤其重要。因此,邊緣電腦視覺支援開發私密、穩健、安全且任務關鍵型的現實世界應用。
由於邊緣人工智慧 (Edge AI) 需要物聯網 (AIoT) 來管理分散式設備,因此邊緣電腦視覺的卓越性能,是以增加技術複雜性為代價的。

分散式
車牌辨識
和車型分析
電腦視覺 AI 應用與應用案例
各行各業的企業正在迅速引入 CV 技術,利用「視覺」電腦解決自動化問題。視覺 AI 技術正在快速發展,使創新和實施新想法、新項目和新應用成為可能,其中包括:
製造業
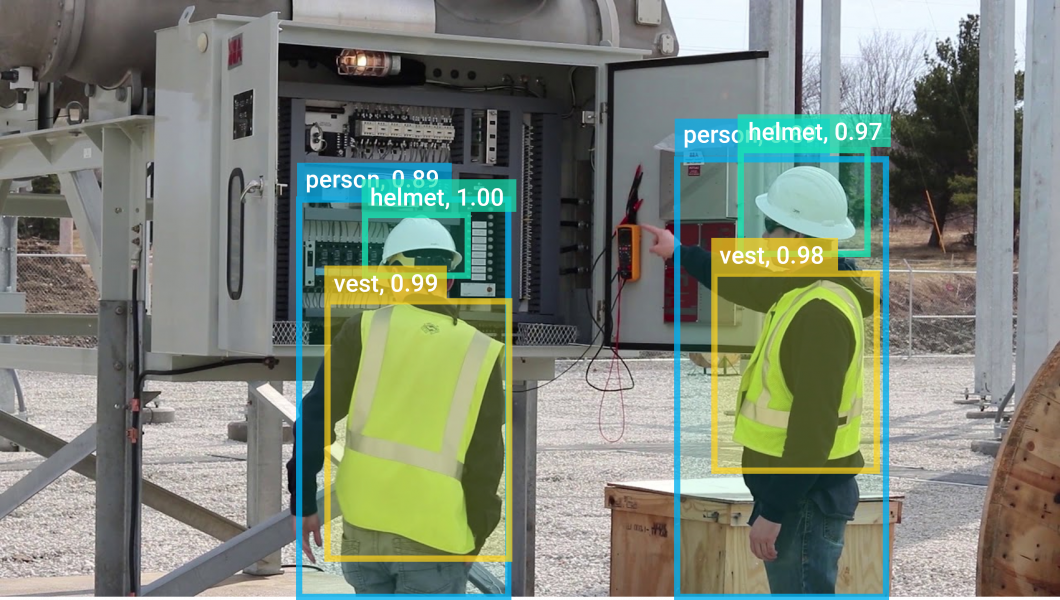
工業電腦視覺在製造業的生產線上,用於自動化產品檢測、物件計數、流程自動化,並透過個人防護裝備 (PPE) 檢測和口罩檢測,來提高員工安全。

醫療保健業
在電腦視覺在醫療保健領域的應用中,一個突出的例子是自動人體跌倒偵測,用於建立跌倒風險評分,並觸發警報。

安全監控
在影像監控和安防領域,人員檢測可用於智慧周界監控。另一個常見的用例是深度人臉偵測和人臉辨識,其準確率高於人類水準。

農業
電腦視覺在農業和耕作中的應用案例,包括自動動物監測以檢測動物福利,以及早期發現疾病和異常情況。

智慧城市專案
作為智慧城市的關鍵策略,用於人群分析、武器偵測、交通分析、車輛計數、自動駕駛汽車/自主駕駛車輛,以及基礎設施檢查。

零售業
例如,零售店的視訊監控攝影機,可以追蹤顧客的運動模式,並進行人數統計或客流量分析,以辨識瓶頸、顧客注意力和等待時間。

保險業
保險業中的電腦視覺利用人工智慧視覺,進行自動化風險管理和評估、索賠管理、視覺檢查和前瞻性分析。
物流業
物流領域的人工智慧願景運用深度學習,來實現人工智慧觸發的自動化,並透過減少人為錯誤、預測性維護,和加速整個供應鏈的營運來節省成本。

製藥業
製藥業的電腦視覺用於包裝和泡罩檢測、膠囊辨識,以及設備清潔的視覺檢查。

擴增實境與虛擬實境
擴增實境和虛擬實境的電腦視覺,透過整合現實世界或虛擬環境感知,創造沉浸式體驗,讓使用者能夠即時與虛擬環境互動。
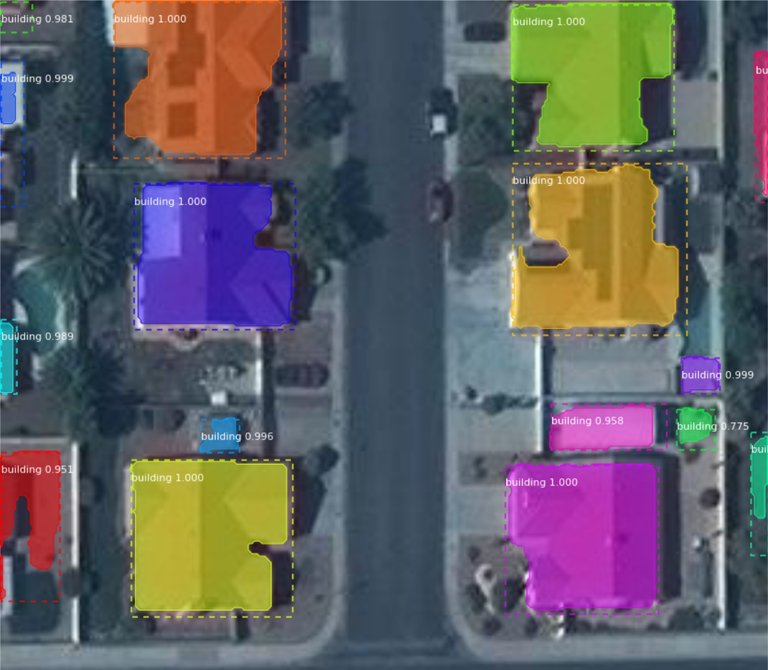
電腦視覺 AI 研究
關鍵研究領域涉及基礎視覺感知任務:
- 物件辨識:確定影像資料,是否包含一個或多個指定或學習到的物體或物件類別。
- 人臉辨識:透過將人臉與資料庫條目,進行比對來影像單一人臉實例。
- 物體偵測:分析特定條件下的影像數據,並定位給定類別的語義物體實例。
- 姿態估計:估計特定物體相對於攝影機的方向和位置。
- 光學字元辨識 (OCR):辨識影像中的字元(車牌號碼、手寫等),通常會結合以有用的格式,對文字進行編碼。
- 場景理解:將影像解析為有意義的片段以進行分析。
- 運動分析:追蹤影像序列或影像中興趣點(關鍵點)或物體(車輛、物體、人體等)的運動。
- 模式辨識:辨識資料中的模式和規律。

什麼是影像分類?
影像分類是電腦視覺的基本組成部分。電腦視覺工程師通常從訓練神經網路辨識影像中的不同物體(即物體偵測)開始。訓練神經網路辨識影像中兩個物體之間的差異,意味著建立一個二分類模型。另一方面,如果影像中有兩個以上的物體,則是多分類問題。
需要注意的是,要成功建立任何可擴展,或可用於生產的圖像分類模型,該模型必須能夠從足夠的數據中學習。遷移學習是一種影像分類技術,它利用現有的架構,這些架構已經過訓練,可以從海量資料樣本中,學習到足夠的知識。然後,學習到的特徵或任務,被用來辨識相似的樣本。這種技術的另一個術語是知識遷移。
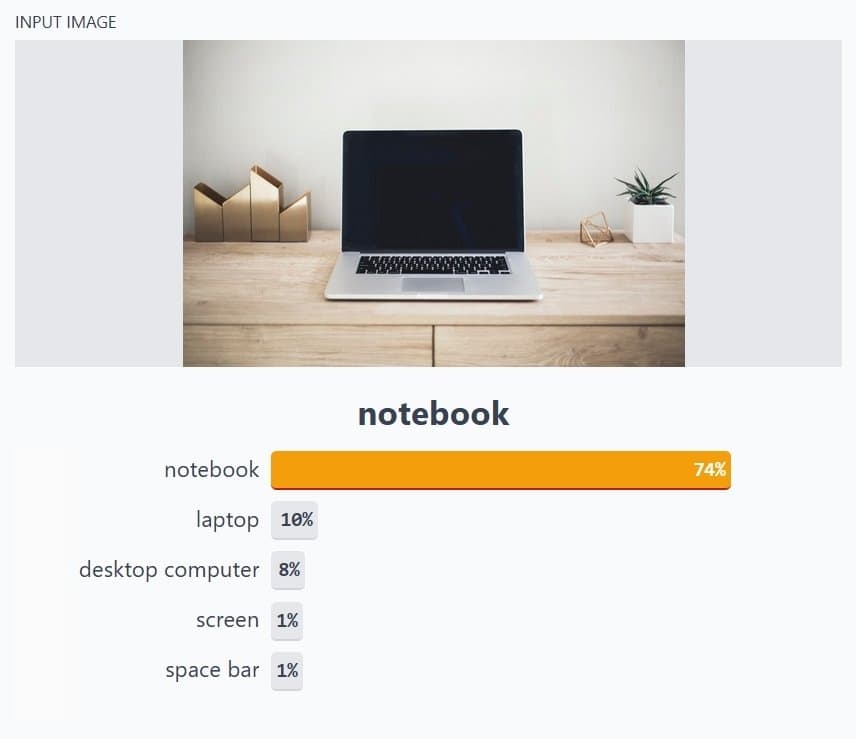
借助遷移學習的概念,電腦視覺工程師利用少量資料,建構了可擴展的商業解決方案。現有的影像分類架構,包括 ResNet-50、ResNet-100、ImageNet、AlexNet、VggNet 等。
什麼是影像處理?
影像處理是人工智慧視覺系統的關鍵環節,因為它涉及對影像進行變換,以提取特定資訊或優化影像,以便用於電腦視覺系統中的後續任務。基本的影像處理技術,包括平滑、銳利化、對比、去雜訊或著色。
事實上,影像處理的標準工具是 OpenCV,它最初由英特爾開發,目前已被Google、豐田、IBM、Facebook 等公司使用。
影像預處理可以去除不必要的資訊,幫助人工智慧模型有效地學習影像的特徵。其目標是透過消除不必要的偽造,來改善影像特徵,並實現更高的分類性能。

影像處理的一個常見應用是超解析度。這項技術通常將低解析度影像,轉換為高解析度影像。超解析度是大多數電腦視覺工程師面臨的一大挑戰,因為他們通常從低品質影像中獲取模型資訊。
什麼是光學字元辨識?
光學字元辨識或光學字元讀取器 (OCR) ,是一種將影像中任何形式的書面或印刷文字,轉換為機器可讀格式的技術。
現有的 OCR 提取架構,包括 EasyOCR、Python-tesseract 或 Keras-OCR。這些機器學習軟體工具,廣泛用於車牌辨識等應用。

什麼是影像分割?
影像分類目的,在辨識影像中不同物件的標籤,而實例分割則試圖找到影像中物件的精確邊界。
影像分割技術有兩種:實例分割和語意分割。實例分割與語義分割的區別在於,它為圖像中特定物件的每個實例,傳回一個唯一的標籤。

什麼是基於視覺 AI 的目標偵測?
目標偵測專注於偵測影像中的目標,並透過一系列影格追蹤該目標。
目標偵測通常應用於影像串流,使用者可以同時追蹤具有唯一標識的多個目標。常用的目標偵測架構包括 AI 視覺演算法 YOLO、R-CNN 或 MobileNet。

什麼是姿勢估計?
姿勢估計使電腦能夠理解人體姿勢。姿勢估計的常用架構,包括 OpenPose、PoseNet、DensePose 或 MeTRAbs。這些架構可用於解決現實世界的問題,例如透過姿勢進行犯罪偵查,或進行人體工學評估,以改善組織健康狀況。


0 comments:
張貼留言