Far Field Speech Recognition: Adopted with ASR such as Amazon Alexa

來源:infoq.cn 作者:Derrick Mwiti

基於電腦的人類語音辨識與處理能力,被統稱為語音辨識。目前,這項技術被廣泛用於驗證系統中的某些用戶,以及面向谷歌智慧助手、Siri 或者 Cortana 等智慧設備下達指令。從本質上講,我們透過儲存人聲與訓練自動語音辨識系統,以發現語音當中的詞彙與表達模式。在本文中,我們將一同瞭解幾篇旨在利用機器學習與深度學習技術,解決這一難題的重要論文。
Deep Speech 1: 實現端到端語音辨識的向上擴展
本文作者來自百度研究所的矽谷人工智慧實驗室。Deep Speech 1 不需要音素字典,而是使用經過優化的 RNN 訓練系統,旨在利用多個 GPU 實現性能提升。該模型在 Switchboard 2000 Hub5 數據集上,實現 16% 的錯誤率。之所以使用 GPU,是因為其需要投入數千小時進行模型數據訓練。此外,該模型還能夠有效對嘈雜的語音採集環境。
Deep Speech: Scaling up end-to-end speech recognition
Deep Speech 的主要構建單元,是一套遞歸神經網路,其已經完成訓練,能夠攝取語音頻譜圖,並生成英文文本轉錄結果。RNN 的目的在於將輸入序列,轉換為轉錄後的字符概率序列。
RNN 擁有五層隱藏單元層,前三層為非遞歸性質。在各個時間步中,這些非遞歸層分別處理獨立數據。第四層為具有兩組隱藏單元的雙向遞歸層。其中一組進行正向遞歸,另一組則為反向遞歸。在預測完成之後,模型會計算 connectionist temporal classification(CTC)損失函數以衡量預測誤差。訓練則利用 Nesterov 的加速梯度法完成。
Deep Speech 1: 實現端到端語音辨識的向上擴展
本文作者來自百度研究所的矽谷人工智慧實驗室。Deep Speech 1 不需要音素字典,而是使用經過優化的 RNN 訓練系統,旨在利用多個 GPU 實現性能提升。該模型在 Switchboard 2000 Hub5 數據集上,實現 16% 的錯誤率。之所以使用 GPU,是因為其需要投入數千小時進行模型數據訓練。此外,該模型還能夠有效對嘈雜的語音採集環境。
Deep Speech: Scaling up end-to-end speech recognition
Deep Speech 的主要構建單元,是一套遞歸神經網路,其已經完成訓練,能夠攝取語音頻譜圖,並生成英文文本轉錄結果。RNN 的目的在於將輸入序列,轉換為轉錄後的字符概率序列。
RNN 擁有五層隱藏單元層,前三層為非遞歸性質。在各個時間步中,這些非遞歸層分別處理獨立數據。第四層為具有兩組隱藏單元的雙向遞歸層。其中一組進行正向遞歸,另一組則為反向遞歸。在預測完成之後,模型會計算 connectionist temporal classification(CTC)損失函數以衡量預測誤差。訓練則利用 Nesterov 的加速梯度法完成。
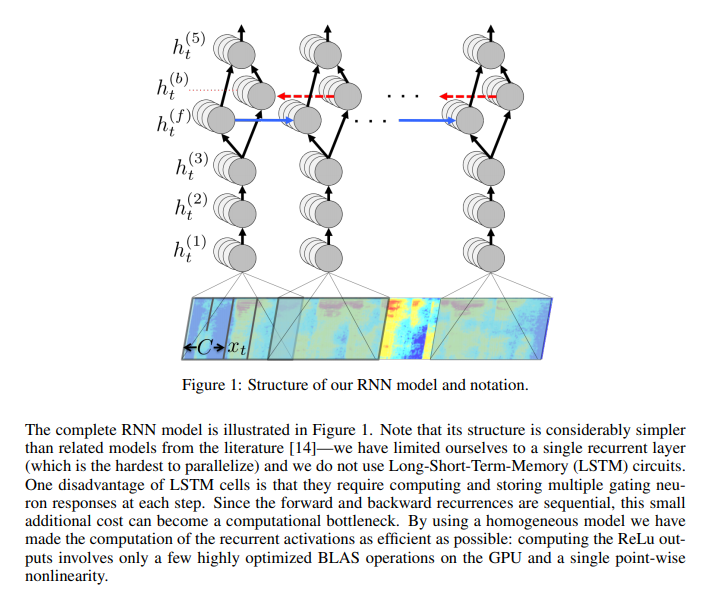
為了減少訓練期間的方差,作者們在前饋層當中,添加了 5% 到 10% 的棄用率。然而,這並不會影響到遞歸隱藏激活函數。此外,作者還在系統當中,整合了一套 N-gram 語言醋,這是因為 N-gram 模型,能夠輕鬆利用大規模,未標記文本語料庫進行訓練。下圖所示為 RNN 轉錄示例:

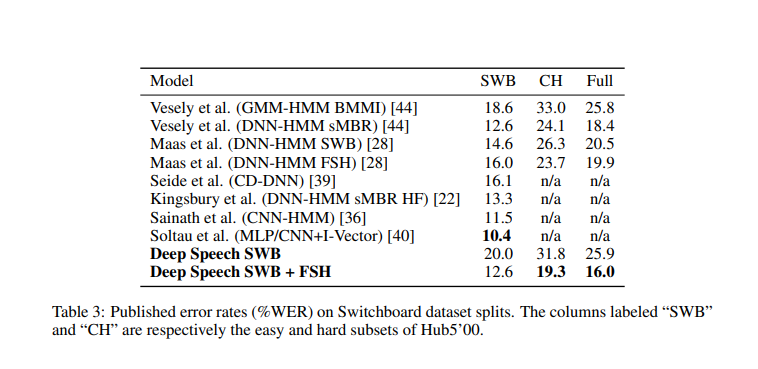
下圖為本模型與其它模型的性能比較結果:
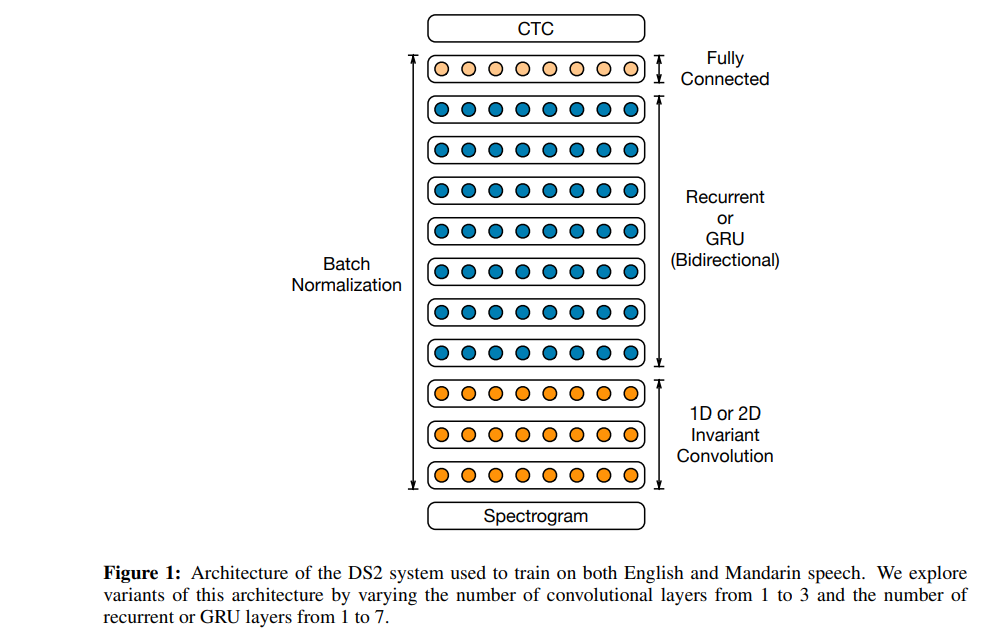
Deep Speech 2:英語與國語的端到端語音辨識
在 Deep Speech 的第二次更新換代當中,作者利用端到端深度學習方法,辨識國語與英語語音。
此次提出的模型能夠處理不同的語言,以及其中的重音,且繼續保持對嘈雜環境的適應能力。作者利用高性能計算(HPC)技術實現了 7 倍於上代模型的速度增量。在他們的數據中心內,作者們利用 GPU 實現 Batch Dispatch。
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
其英語語音系統,利用 11940 個小時的語音音頻訓練而成,而國語系統則使用 9400 小時的語音音頻訓練而成。在訓練過程中,作者們利用數據合成,來進一步增加數據量。
這套模型中使用的架構多達 11 層,由雙向遞歸層與卷積層組成。該模型的計算能力,比 Deep Speech 1 快 8 倍。作者利用 Batch Normalization 進行優化。
在激活函數方面,作者們使用了限幅整流線性(ReLU)函數。從本質上講,這種架構與 Deep Speech 1 類似。該架構是一套經過訓練的遞歸神經網路,用於攝取語音音頻譜圖與輸出文本轉錄。此外,他們還利用 CTC 損失函數進行模型訓練。
Deep Speech 2:英語與國語的端到端語音辨識
在 Deep Speech 的第二次更新換代當中,作者利用端到端深度學習方法,辨識國語與英語語音。
此次提出的模型能夠處理不同的語言,以及其中的重音,且繼續保持對嘈雜環境的適應能力。作者利用高性能計算(HPC)技術實現了 7 倍於上代模型的速度增量。在他們的數據中心內,作者們利用 GPU 實現 Batch Dispatch。
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
其英語語音系統,利用 11940 個小時的語音音頻訓練而成,而國語系統則使用 9400 小時的語音音頻訓練而成。在訓練過程中,作者們利用數據合成,來進一步增加數據量。
這套模型中使用的架構多達 11 層,由雙向遞歸層與卷積層組成。該模型的計算能力,比 Deep Speech 1 快 8 倍。作者利用 Batch Normalization 進行優化。
在激活函數方面,作者們使用了限幅整流線性(ReLU)函數。從本質上講,這種架構與 Deep Speech 1 類似。該架構是一套經過訓練的遞歸神經網路,用於攝取語音音頻譜圖與輸出文本轉錄。此外,他們還利用 CTC 損失函數進行模型訓練。
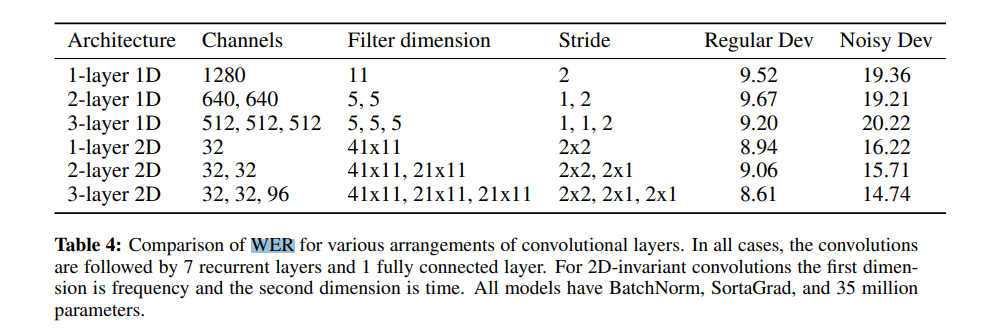
下圖所示,為各種卷積層排列情況下的單詞錯誤率比較結果。
下圖所示為 Deep Speech 1 與 Deep Speech 2 的,單詞錯誤率比較結果。Deep Speech 2 的單詞錯誤率明顯更低。

作者們使用《華爾街日報》新聞文章,組成的兩套測試數據集,對系統進行了基準測試。該模型在四分之三的情況下,實現了優於人類的單詞錯誤率。此外,系統中還使用到 LibriSpeech 語料庫。
利用雙向遞歸 DNN 實現首過大詞彙量連續語音辨識
本篇論文的作者來自史丹佛大學。在本文中,他們提出一種利用主意模型,與神經網路執行首過大詞彙量語音辨識的技術。
First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs
利用 connectionist temporal classification(CTC)損失函數訓練神經網路。CTC 使得作者們得以訓練出一套神經網路,並在預測《華爾街日報》LVCSR 語料庫中的語言字符序列時,獲得低於 10% 的字符錯誤率(CER)。
他們將 N-gram 語言模型,與 CTC 訓練而成的神經網路相結合。該模型的架構,為反應擴散神經網路(RDNN)。利用整流器非線性的一套修改版本,新系統修剪了大型激活函數,以防止其在網路訓練期間發生發散。以下為 RDNN 得出的字符錯誤率結果。
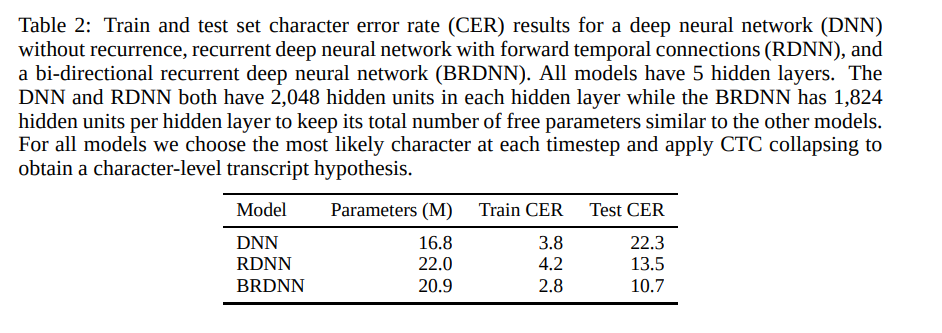
人與機器間英語會話電話語音辨識
來自 IBM 研究院的作者們,希望驗證目前的語音辨識技術,是否已經能夠與人類相媲美。他們還在論文中提出了一套聲學與語言建模技術。
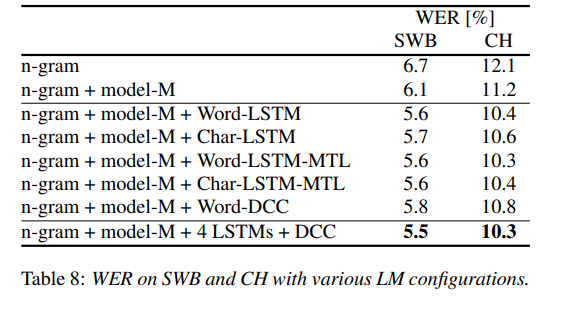
聲學側涉及三大模型:其一為具有多個特徵輸入的 LSTM,其二為利用說話者,對抗性多任務學習,訓練而成的 LSTM,其三則為具有 25 個卷積層的殘差網路。
該語言模型利用字符 LSTM ,與卷積 WaveNet 式語言模型。作者們的英語會話電話 LVCSR 系統,在 Switchboard/CallHome 子集(SWB/CH)上,分別獲得了 5.5%/10.3% 的單詞錯誤率。
English Conversational Telephone Speech Recognition by Humans and Machines
本文使用的架構,包括 4 到 6 個雙向層,每層 1024 個單;外加一個線性瓶頸層,包含 256 個單元;一個輸出層,包含 32000 個單元。訓練則涵蓋 14 次交叉熵,而後使用強化 MMI(最大互資訊)標準,進行 1 輪隨機梯度下降(SGD)序列訓練。
作者們透過添加交叉熵損失函數的擴展梯度,來實現平滑效果。LSTM 利用 Torch 配合 CuDNN 5.0 版本後端實現。各模型的交叉熵訓練,則在單一英偉達 K80 GPU 設備上完成,且每輪 700 M 樣本訓練週期約為兩周。
人與機器間英語會話電話語音辨識
來自 IBM 研究院的作者們,希望驗證目前的語音辨識技術,是否已經能夠與人類相媲美。他們還在論文中提出了一套聲學與語言建模技術。
聲學側涉及三大模型:其一為具有多個特徵輸入的 LSTM,其二為利用說話者,對抗性多任務學習,訓練而成的 LSTM,其三則為具有 25 個卷積層的殘差網路。
該語言模型利用字符 LSTM ,與卷積 WaveNet 式語言模型。作者們的英語會話電話 LVCSR 系統,在 Switchboard/CallHome 子集(SWB/CH)上,分別獲得了 5.5%/10.3% 的單詞錯誤率。
English Conversational Telephone Speech Recognition by Humans and Machines
本文使用的架構,包括 4 到 6 個雙向層,每層 1024 個單;外加一個線性瓶頸層,包含 256 個單元;一個輸出層,包含 32000 個單元。訓練則涵蓋 14 次交叉熵,而後使用強化 MMI(最大互資訊)標準,進行 1 輪隨機梯度下降(SGD)序列訓練。
作者們透過添加交叉熵損失函數的擴展梯度,來實現平滑效果。LSTM 利用 Torch 配合 CuDNN 5.0 版本後端實現。各模型的交叉熵訓練,則在單一英偉達 K80 GPU 設備上完成,且每輪 700 M 樣本訓練週期約為兩周。
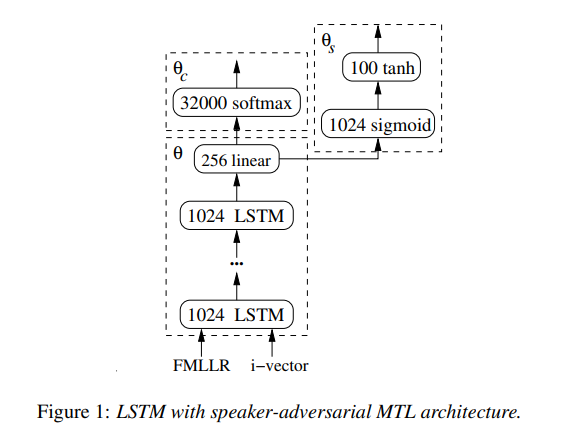
對於卷積網路聲學建模,作者們訓練了一套殘差網路。下表所示為幾種 ResNet 架構,及其在測試數據上的實際性能。
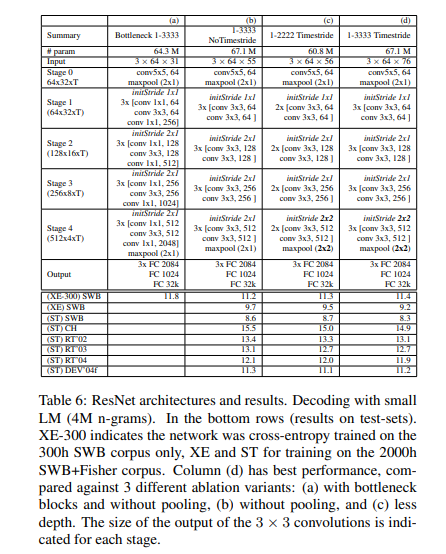
下圖所示為殘差網路,如何適應聲學建模。該網路包含 12 個殘差單元,30 個權重層,以及 6710 萬個參數,利用 Nesterov 加速梯度進行訓練,學習率為 0.03,動量為 0.99。
CNN 同樣採用 Torch ,配合 cuDNN 5.0 版本後端。交叉熵訓練週期為 80 天,涉及 15 億個樣本,採用一塊英偉達 K80 GPU,每 GPU 64 個批次。
透過下圖,可以看到 LSTM 與 ResNets 的錯誤率:
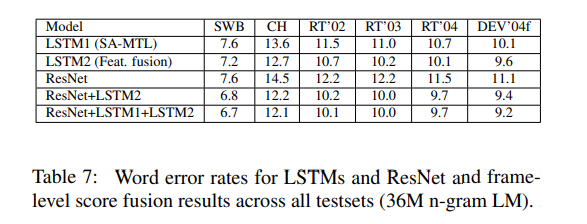
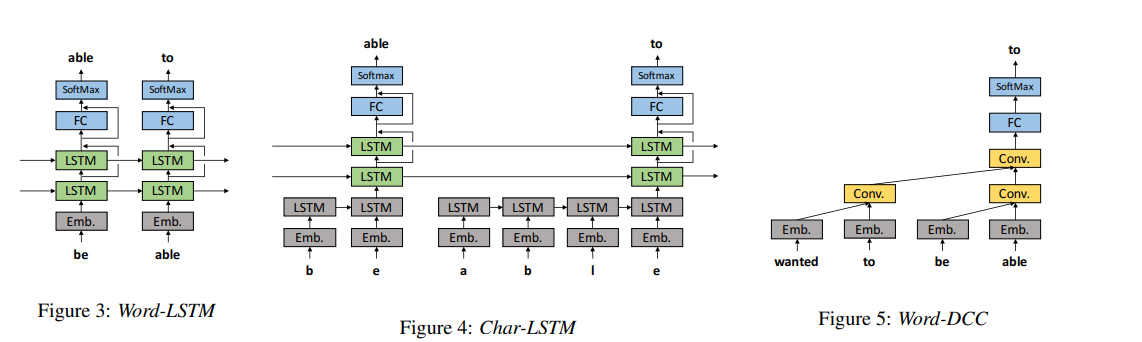
作者們還嘗試了四種 LSTM 語言模型,分別為 WordLSTM、Char-LSTM、Word-LSTM-MTL 以及 Char-LSTM-MTL。下圖所示為這四種模型的架構。
其中 Word-LSTM 擁有一個字嵌入層,兩個 LSTM 層,一個全連接層,以及一個 softmax 層。Char-LSTM 則擁有一個用於透過字符序列,估算嵌入的 LSTM 層。Word-LSTM 與 Char-LSTM 都使用交叉熵損失函數,來預測下一個單詞。顧名思義,Word-LSTM-MTL 與 Char-LSTM-MTL 當中,引入了多任務學習(MTL)機制。
WordDCC 由一個單詞嵌入層、多個具有擴張的因果卷積層、卷積層、完全連接層、softmax 層,以及殘差連接共同組成。
Wav2Letter++: 最快的開源語音辨識系統
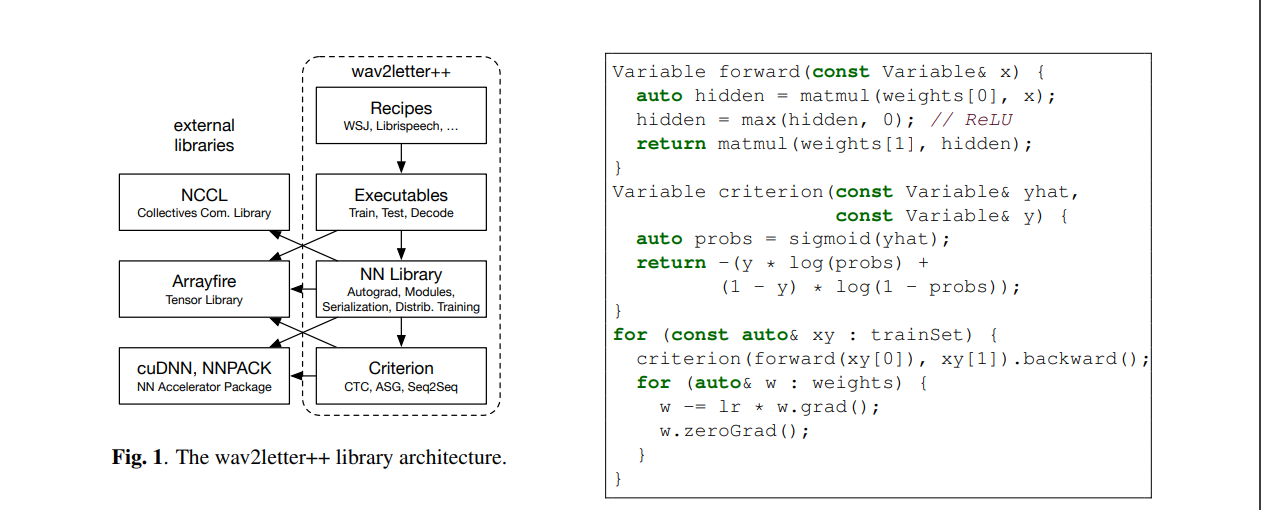
來自 Facebook AI Research 的作者們,提出一套開源深度學習語音辨識框架——Wav2Letter。該框架由 C++ 編寫,並使用 ArraFire 張量庫。
wav2letter++: The Fastest Open-source Speech Recognition System
之所以使用 ArrayFire 張量庫,是因為它能夠在多個後端上執行,包括 CUDA GPU 後端與 CPU 後端,從而顯著提升執行速度。與其它 C++ 張量庫相比,在 ArrayFire 中建構及使用數組,也相對更容易。圖左所示為如何建構及訓練,具有二進制交叉熵損失函數的單層 MLP(多層感知器)。
Wav2Letter++: 最快的開源語音辨識系統
來自 Facebook AI Research 的作者們,提出一套開源深度學習語音辨識框架——Wav2Letter。該框架由 C++ 編寫,並使用 ArraFire 張量庫。
wav2letter++: The Fastest Open-source Speech Recognition System
之所以使用 ArrayFire 張量庫,是因為它能夠在多個後端上執行,包括 CUDA GPU 後端與 CPU 後端,從而顯著提升執行速度。與其它 C++ 張量庫相比,在 ArrayFire 中建構及使用數組,也相對更容易。圖左所示為如何建構及訓練,具有二進制交叉熵損失函數的單層 MLP(多層感知器)。
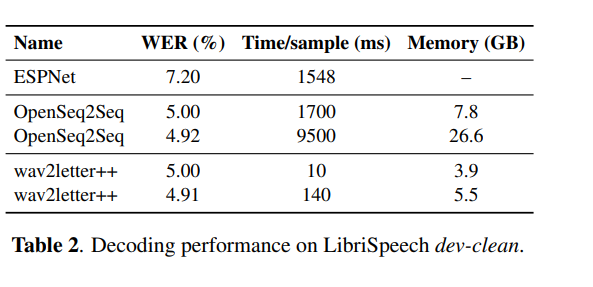
該模型利用《華爾街日報》(WSJ)數據集進行了測試,共使用兩種類型的神經網路架構,進行訓練時間評估:遞歸,包含 3000 萬個參數;純卷積,包含 1 億個參數。下圖所示為該模型,在 LibreSpeech 上的單詞錯誤率。
SpecAugment: 一種用於自動語音辨識的簡單數據增強方法
Google Brain 的作者們,預設了一種簡單的語音辨識數據增強方法,並將其命名為 SpecAugment。該方法能夠對輸入音頻的對數譜圖進行操作。
在 LibreSpeech test-other 集中,作者們在無需語言模型的前提下,實現了 6.85% 的 WER(單詞錯誤率),而使用語言模型後, WER 進一步改善至 5.8%。對於 Switchboard,該方法在 Switchboard/CallHome 上,分別得到 7.2%/14.6% 的單詞錯誤率。
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
利用這種方法,作者們得以訓練出一套,名為 https://arxiv.org/abs/1508.01211 \t _blank">Listen, Attend and Spell (LAS) 的端到端 ASR(自動語音辨識)網路。其中使用到的數據增強策略包括 time warping 、https://journals.sagepub.com/doi/10.1177/1084713808326455 \t_blank">frequencymasking以及https://journals.sagepub.com/doi/10.1177/1084713808326455 \t _blank">time masking 等等。
SpecAugment: 一種用於自動語音辨識的簡單數據增強方法
Google Brain 的作者們,預設了一種簡單的語音辨識數據增強方法,並將其命名為 SpecAugment。該方法能夠對輸入音頻的對數譜圖進行操作。
在 LibreSpeech test-other 集中,作者們在無需語言模型的前提下,實現了 6.85% 的 WER(單詞錯誤率),而使用語言模型後, WER 進一步改善至 5.8%。對於 Switchboard,該方法在 Switchboard/CallHome 上,分別得到 7.2%/14.6% 的單詞錯誤率。
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
利用這種方法,作者們得以訓練出一套,名為 https://arxiv.org/abs/1508.01211 \t _blank">Listen, Attend and Spell (LAS) 的端到端 ASR(自動語音辨識)網路。其中使用到的數據增強策略包括 time warping 、https://journals.sagepub.com/doi/10.1177/1084713808326455 \t_blank">frequencymasking以及https://journals.sagepub.com/doi/10.1177/1084713808326455 \t _blank">time masking 等等。

在這套 LAS 網路當中,輸入對數譜圖被傳遞至一個雙層卷積神經網路(CNN)當中,且步長為 2。該 CNN 的輸出,則進一步透過具有 d 個堆疊的雙向 LSTM 編碼器 —— 其中單元大小為 w,用以生成一系列 attention 向量。
各 attention 向量被饋送至一個單元維度,為 w 的雙層 RNN 解碼器中,並由其輸出轉錄標記。作者們利用一套 16 k 的 Word Piece Model ,對 LibriSpeech 語料庫,以前主一套 1 k 的 Word Piece Model 對 Switchboard 進行文本標記化。最終轉錄結果由集束搜索獲取,集束大小為 8。
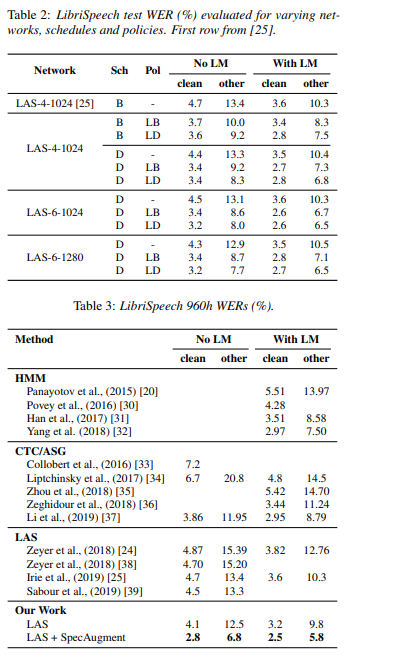
下圖所示為 LAS + SpecAugment 得出的單詞錯誤率性能。
Wav2Vec: 用於語音辨識的無監督預訓練方法
來自 Facebook AI Research 的作者們,透過學習原始音頻的表達,來探索如何以無監督方式,實現語音辨識的預訓練。由此產生的結果就是 Wav2Vec,一套在大規模未標記音頻數據集上,訓練得出的模型。
由此獲得的表示將用於改進聲學模型訓練。透過噪聲對比二進制分類任務,對一套簡單的多層卷積神經網路,進行預訓練及優化,得出的 Wav2Vec 成功在 nov92 測試數據集上,達到 2.43% 的 WER。
wav2vec: Unsupervised Pre-training for Speech Recognition
預訓練中使用的方法,是優化該模型以實現利用單一上下文,進行未來樣本預測。該模型將原始音頻信號作為輸入,而後應用編碼器網路與上下文網路。
編碼器首先將音頻信號嵌入潛在空間中,且上下文網路負責組合該編碼器的多個時間步,從而得出完成上下文化的表示。接下來,從兩套網路當中計算出目標函數。
Wav2Vec: 用於語音辨識的無監督預訓練方法
來自 Facebook AI Research 的作者們,透過學習原始音頻的表達,來探索如何以無監督方式,實現語音辨識的預訓練。由此產生的結果就是 Wav2Vec,一套在大規模未標記音頻數據集上,訓練得出的模型。
由此獲得的表示將用於改進聲學模型訓練。透過噪聲對比二進制分類任務,對一套簡單的多層卷積神經網路,進行預訓練及優化,得出的 Wav2Vec 成功在 nov92 測試數據集上,達到 2.43% 的 WER。
wav2vec: Unsupervised Pre-training for Speech Recognition
預訓練中使用的方法,是優化該模型以實現利用單一上下文,進行未來樣本預測。該模型將原始音頻信號作為輸入,而後應用編碼器網路與上下文網路。
編碼器首先將音頻信號嵌入潛在空間中,且上下文網路負責組合該編碼器的多個時間步,從而得出完成上下文化的表示。接下來,從兩套網路當中計算出目標函數。
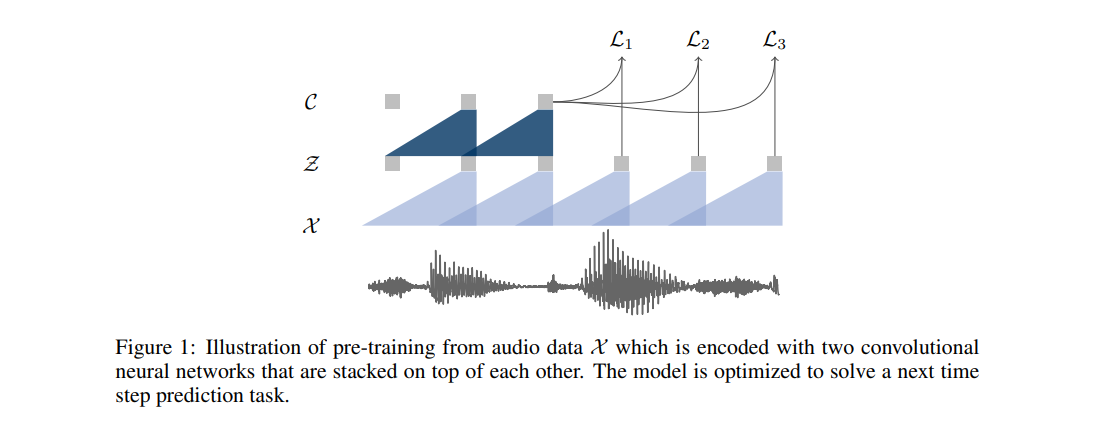
編碼器與上下文網路中的各層,包括具有 512 個信道的因果卷積層,一個組歸一化層,以及一項 ReLU 非線性激活函數。在訓練期間,由上下文網路生成的表示被饋送,至聲學模型當中。聲學模型的訓練與評估利用 wav2letter++ 工具包完成。
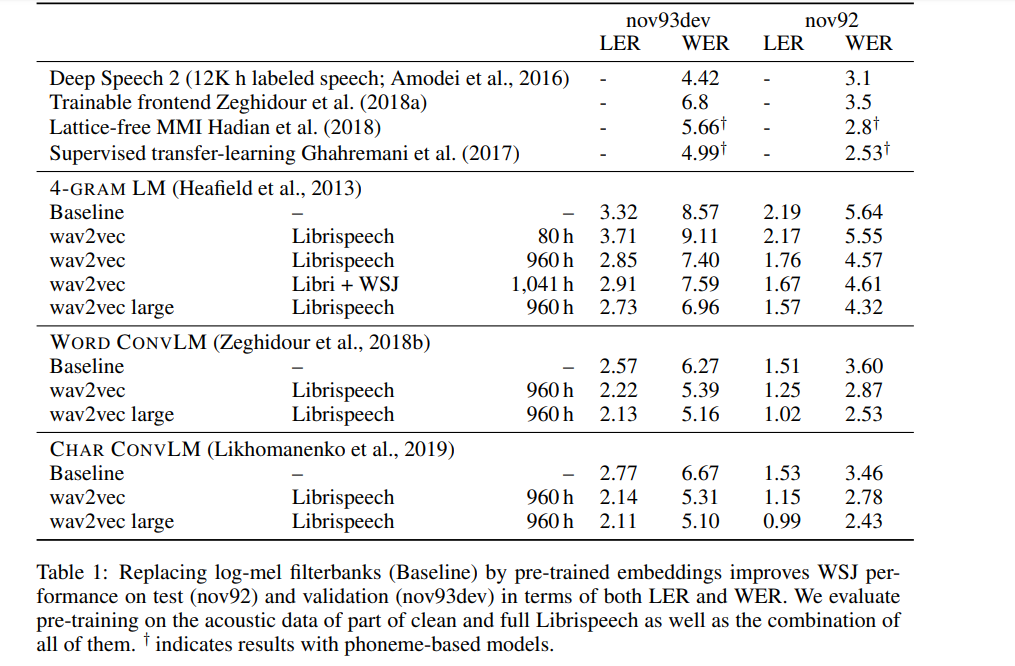
在解碼方面,作者們使用由 WSJ 語言建模數據集上,訓練得出的字典與單獨的語言模型實現。
下圖所示,為此模型與其它語音辨識模型的,單詞錯誤率比較結果。
用於 ASR 的可擴展多語料庫神經語言模型
在本文當中,Amazon Alexa 的作者們,為使用大規模 ASR 系統的神經語言模型時,出現的一些挑戰帶來解決方案。
Scalable Multi Corpora Neural Language Models for ASR
作者們試圖解決的挑戰包括:
- 在多個異構語料庫上訓練 NLM
- 通過將首過模型中的聯繫人名稱等類傳遞給 NLM,以建立個性化神經語言模型(NLM)
- 將 NLM 納入 ASR 系統,同時控制延遲影響
對於立足異構語料庫實現學習這項任務,作者們利用隨機梯度下降的變種,估計神經網路的參數。這種方法要取得成功,要求各小批次必須為學習數據集的獨立且相同(iid)樣本。
透過以相關性為基礎,從各個語料庫中,抽取樣本以隨機建構小批次數據子集,這套系統得以為各個數據源,建構 N-gram 模型,並在開發集上,對用於相關性加權的線性,插值加權進行優化。
透過從 NLM 上採樣大文本語料庫,並利用該語料庫估算 N-gram 模型,這套系統得以建構起 NLM 的 N-gram 近似模式,從而為首過 LM 生成合成數據。
另外,作者們利用一套子單詞 NLM 生成合成數據,從而確保由此獲得的語料庫,不受限於當前 ASR 系統版本中的詞彙儲備。模型中使用的書面文本語料庫,總計包含超過 500 億個單詞。NLM 架構由兩個長 - 短期記憶投射遞歸神經網路(LSTMP)層組成,每個層包含 1024 個隱藏單元,投向至 512 維度。各層之間存在殘差連接。
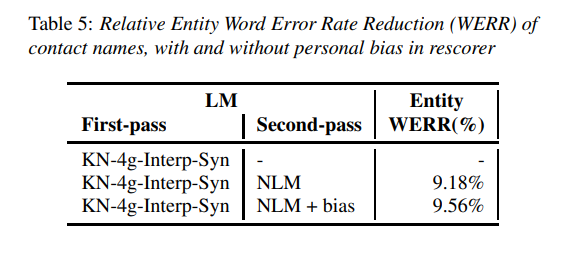
下圖所示為該模型給出的一部分結果。其透過從 NLM 生成的合成數據,獲得了我 1.6% 的相對 WER。
用於 ASR 的可擴展多語料庫神經語言模型
在本文當中,Amazon Alexa 的作者們,為使用大規模 ASR 系統的神經語言模型時,出現的一些挑戰帶來解決方案。
Scalable Multi Corpora Neural Language Models for ASR
作者們試圖解決的挑戰包括:
- 在多個異構語料庫上訓練 NLM
- 通過將首過模型中的聯繫人名稱等類傳遞給 NLM,以建立個性化神經語言模型(NLM)
- 將 NLM 納入 ASR 系統,同時控制延遲影響
對於立足異構語料庫實現學習這項任務,作者們利用隨機梯度下降的變種,估計神經網路的參數。這種方法要取得成功,要求各小批次必須為學習數據集的獨立且相同(iid)樣本。
透過以相關性為基礎,從各個語料庫中,抽取樣本以隨機建構小批次數據子集,這套系統得以為各個數據源,建構 N-gram 模型,並在開發集上,對用於相關性加權的線性,插值加權進行優化。
透過從 NLM 上採樣大文本語料庫,並利用該語料庫估算 N-gram 模型,這套系統得以建構起 NLM 的 N-gram 近似模式,從而為首過 LM 生成合成數據。
另外,作者們利用一套子單詞 NLM 生成合成數據,從而確保由此獲得的語料庫,不受限於當前 ASR 系統版本中的詞彙儲備。模型中使用的書面文本語料庫,總計包含超過 500 億個單詞。NLM 架構由兩個長 - 短期記憶投射遞歸神經網路(LSTMP)層組成,每個層包含 1024 個隱藏單元,投向至 512 維度。各層之間存在殘差連接。
下圖所示為該模型給出的一部分結果。其透過從 NLM 生成的合成數據,獲得了我 1.6% 的相對 WER。
總結
到這裡,我們已經回顧了最近一段時間,常見於各類環境中的自動語音辨識技術。
以上提到的論文/摘要當中,也包含其代碼實現鏈接,期待大家發佈您自己的實際測試結果。
原文鏈接:
總結
到這裡,我們已經回顧了最近一段時間,常見於各類環境中的自動語音辨識技術。
以上提到的論文/摘要當中,也包含其代碼實現鏈接,期待大家發佈您自己的實際測試結果。
原文鏈接:

0 comments:
張貼留言