Deep Learning in Security—An Empirical Example in User and Entity Behavior Analytics UEBA


影像分類/行為辨識,是電腦視覺領域中,非常有挑戰性的課題,因為其不僅僅要分析目標體的空間資訊,還要分析時間維度上的資訊,如何更好的提取出空間 - 時間特徵是問題的關鍵。本文總結了該領域的技術進展,和相關數據集,技術進展從傳統特徵法,到深度學習中的 3DCNN,LSTM,Two-Stream 等。
1 影像分類/行為辨識問題

首先我們要明確這是一個什麼問題,基於影像的行為辨識,包括兩個主要問題,即行為定位和行為辨識。行為定位即找到有行為的影像片段,與 2D 圖像的目標定位任務相似。而行為辨識即對該影片片段的行為,進行分類辨識,與 2D 圖像的分類任務相似。
本文聚焦的是行為辨識,即對整個影像輸入序列,進行影像分類,一般都是經過裁剪後的影像切片。接下來從數據集的發展,傳統方法,深度學習方法幾個方向進行總結。
2 影像分類 / 行為分析重要數據集
深度學習任務的提升,往往伴隨著數據集的發展,影像分類 / 行為辨識相關的數據集非常多,這裡先給大家介紹,在論文評測中最常見的 3 個數據集。
2.1 HMDB-51
HMDB-51 共 51 個類別,6766 個短片。
数据集地址:http://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/#dataset ,發佈於 2011 年。

數據來源非常廣泛,包括電影,一些現有的公開數據集,YouTube 影片等。從中選擇了 51 個類別,每一個類別包含 101 個以上影片。
分為 5 大類:
- 常見的臉部動作 (smile,laugh,chew,talk)
- 複雜的臉部動作 (smoke,eat,drink)
- 常見的肢體動作 (climb,dive,jump)
- 複雜的肢體動作 (brush hair,catch,draw sword)
- 多人交互肢體動作 (hug,kiss,shake hands)
下面是其中一些維度的統計,包括姿態,相機運動等。
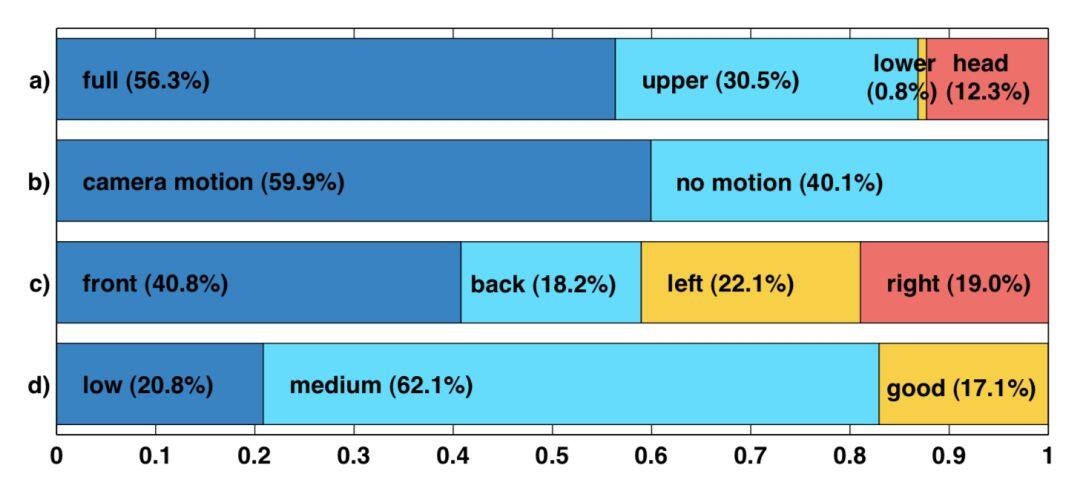

51 個類別的展示如下:
2.2 UCF-101
UCF-101 共 101 個類別,13320 個短片。數據集地址: https://www.crcv.ucf.edu/research/data-sets/human-actions/ucf101/ ,發佈於 2012 年。
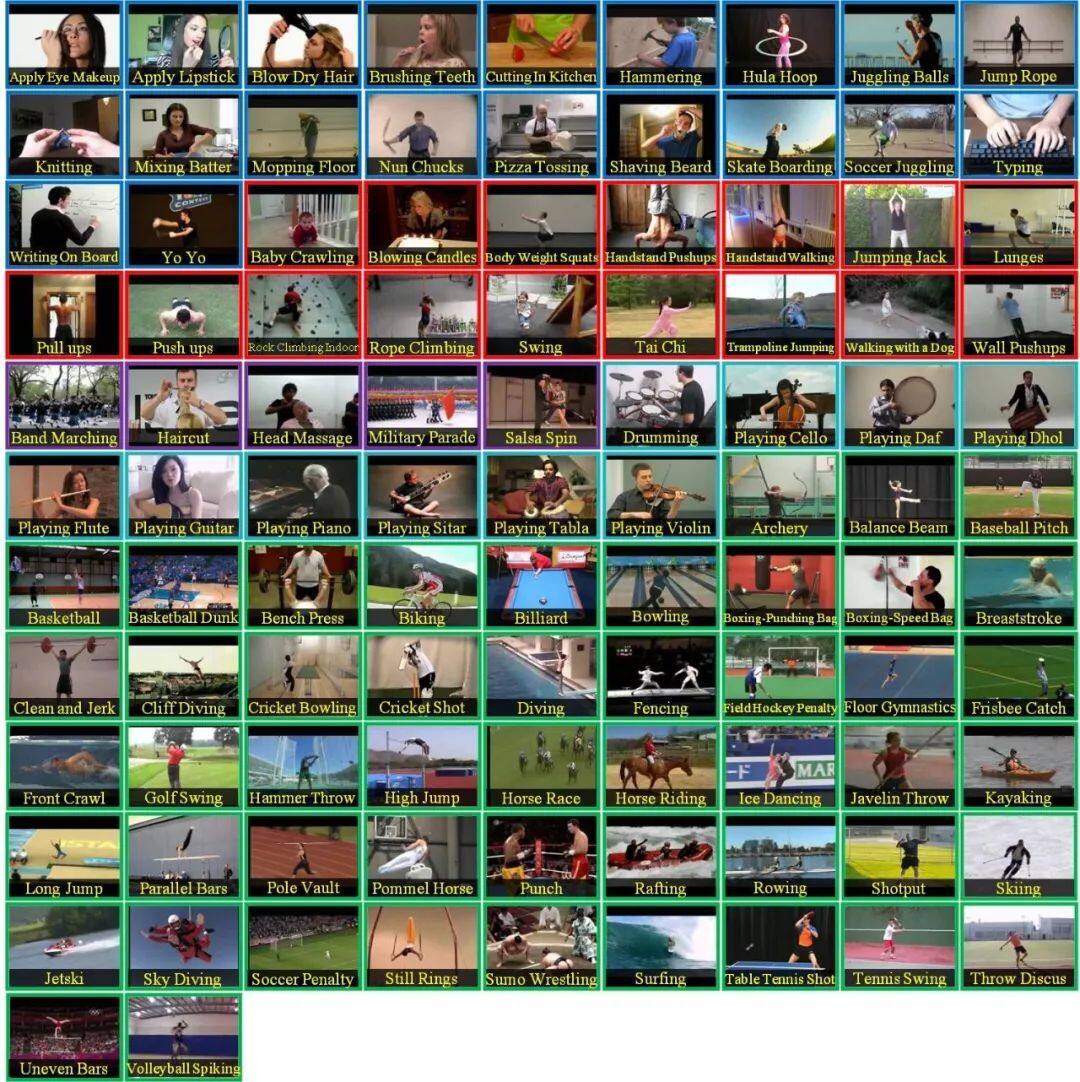
UCF-101 是目前動作類別數、樣本數最多的數據集之一,包含 5 大類動作:人與物體互動、人體動作、人與人互動、樂器演奏、體育運動。總共包括在自然環境下 101 種人類動作,每一類由 25 個人做動作,每個人做 4-7 組,影片大小為 320×240。
正因為類別眾多,加上在動作的採集上,具有非常大的多樣性,如相機運行、外觀變化、姿態變化、物體比例變化、背景變化等等,所以也成為了當前難度最高的,動作類數據集挑戰之一。
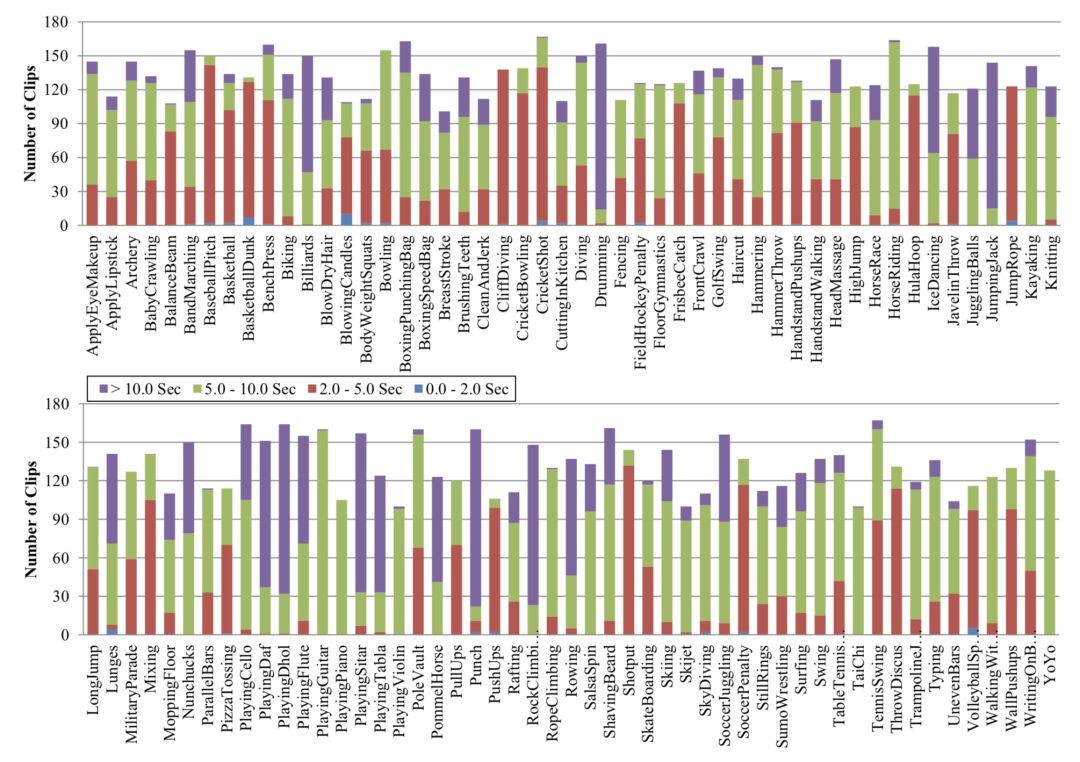
各個類別的分布如上,相對還是比較均勻的,UCF-101 是影片分類 / 行為辨識方法必須評測的標準。
2.3 Kinetics-700 dataset
Kinetics-700 dataset 被用於 ActivityNet 比賽,包含約 650000 個影片,700 個類別。
數據集地址: https://deepmind.com/research/open-source/open-source-datasets/kinetics/ ,發佈於 2019 年。
ActivityNet 比賽始於 2016 的 CVPR,是與 ImageNet 齊名的在影像理解方面最重要的比賽。在這個比賽下的 Task A–Trimmed Action Recognition 比賽,是一個影像分類比賽,2019 年的比賽使用 kinetics-700 數據集,在此之前還有 2017 年的 kinetics-400 和 2018 年的 kinetics-600。
數據集是 Google 的 deepmind 團隊提供,每個類別至少 600 個影片以上,每段影片持續 10 秒左右,標注一個唯一的類別。行為主要分為三大類:人與物互動,比如演奏樂器;人人互動,比如握手、擁抱;運動等。即 person、person-person、person-object。
除了以上數據集,比較重要的還有 Sports-1M,YouTube-8M 等,篇幅所限,就不一一描述,大家可以參考文獻。
如果不能下載數據集,可以移步有三 AI 知識星球獲取。
3 傳統有監督特徵提取方法
傳統的方法透過提取關鍵點的特徵,來對影像進行描述,以時空關鍵點,密集軌跡方法等為代表。
3.1 時空關鍵點 (space-time interest points)
基於時空關鍵點的核心思想是:影像圖像中的關鍵點,通常是在時空維度上,發生強烈變化的數據,這些數據反應了目標運動的重要資訊。

比如一個人揮舞手掌,手掌一定會在前後幀中發生最大移動,其周圍圖像數據發生變化最大。而這個人的身體其他部位卻變化很小,數據幾乎保持不變。如果能將這個變化數據提取出來,並且進一步分析其位置資訊,那麼可以用於區分其他動作。
時空關鍵點的提取方法,是對空間關鍵點方法的擴展,空間關鍵點的提取,則是基於多尺度的圖像表達,這裡的時空關鍵點,就是將 2D Harris 角點的檢測方法,拓展到了 3D,具體求解方法非常複雜,讀者需要自行瞭解,篇幅問題就不講述了。
得到了這些點之後,基於點的一次到四次偏導數,組合成一個 34 維的特徵向量,使用 k-means 對這些特徵向量進行了聚類。
除了 harris,經典的 2D 描述子 SIFT ,被拓展到 3D 空間 [3],示意圖如下:
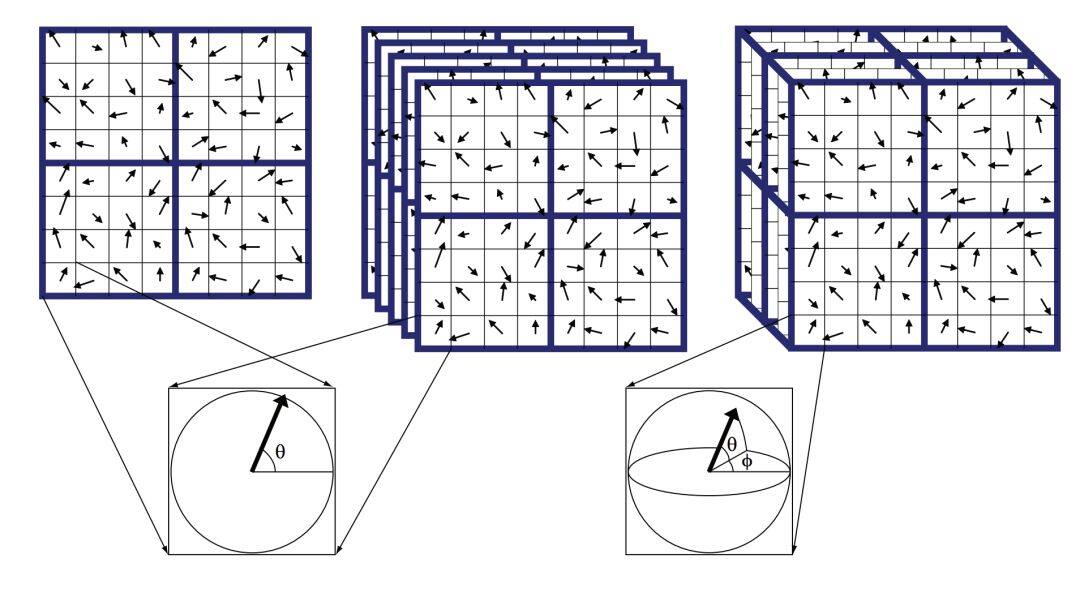
上圖從左至右分別展示了 2D SIFT 特徵,多個時間片的 2D SIFT 特徵,以及 3D SIFT 特徵,後兩者的區別在於計算區域的不同,3D SIFT 的每一個關鍵點包含 3 個值,幅度和兩個角度:
統計關鍵點時空周圍的梯度直方圖,就可以形成特徵描述子,然後對所有的特徵描述子進行 k-means 聚類,劃分類別,形成詞彙「word」。所有不同 word 就構成了一個 vocabulary,每個影像就可以透過,出現在這個 vocabulary 中詞彙的數量來進行描述,最後訓練一個 SVM 或者感知器來進行動作辨識。
除了以上的兩種特徵,還有 HOG3D 等,感興趣的讀者可以自行閱讀。
3.2 密集軌跡 (dense-trajectories)[4]
時空關鍵點是編碼時空坐標中的影像資訊,而軌跡法 iDT(improved Dense Trajectories) 是另一種非常經典的方法,它追蹤給定坐標圖像沿時間的變化。
iDT 算法包含三個步驟:密集採樣特徵點,特徵軌跡跟蹤和基於軌跡的特徵提取。
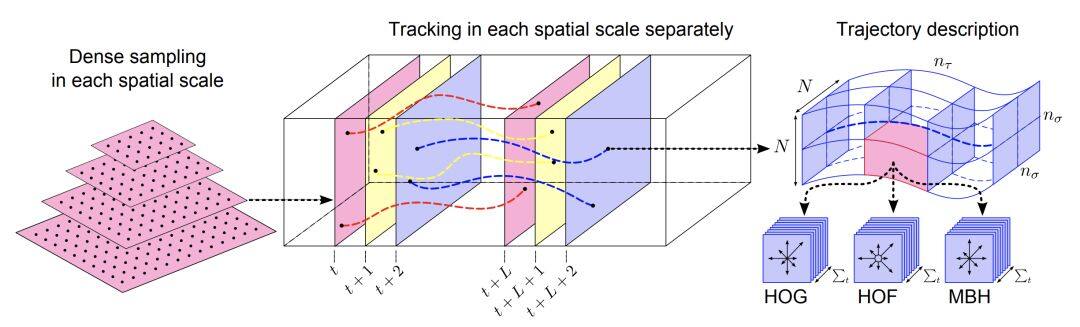
密集採樣是對不同尺度下的圖像,進行規則採樣,不過真正被用於跟蹤等,不是所有點,因為平滑區域的點沒有跟蹤意義,透過計算每個像素點,自相關矩陣的特徵值,並設置閾值去除低於閾值的特徵點,來實現這個選擇。
對軌跡的追蹤是透過光流,首先計算圖像光流速率 (ut, vt),然後透過這個速率,來描述圖像運動軌跡:
wt 是密集光流場,M 是中值濾波器,得到的一系列點形成了一個軌跡。由於軌跡會隨著時間漂移,可能會從初始位置,移動到很遠的地方。
所以論文對軌跡追蹤距離做了限制,首先將幀數限制在 L 內,而且軌跡空間範圍限制在 WxW 範圍,如果被追蹤點不在這個範圍,就重新採樣進行追蹤,這樣可以保證軌跡的密度不會稀疏。
除了軌跡形狀特徵,還提取了 HOG,HOF(histogram of flow) ,以及 MBH(motion boundary histogram) 等特徵。
其中 HOG 特徵計算的是灰度圖像梯度的直方圖,HOF 計算的是光流的直方圖,MBH 計算的是光流梯度的直方圖,也可以理解為在光流圖像上,計算的 HOG 特徵,它反應了不同像素之間的相對運動。
其中 HOG 特徵計算的是灰度圖像梯度的直方圖,HOF 計算的是光流的直方圖,MBH 計算的是光流梯度的直方圖,也可以理解為在光流圖像上,計算的 HOG 特徵,它反應了不同像素之間的相對運動。
以 HOG 特徵為例,在一個長度為 L 的軌跡的各幀圖像上,取特徵點周圍大小為 N×N 的區域,將其在空間和時間上進行劃分。假如空間劃分為 22,時間劃分為 3 份,bins 為 8,則 HOG 特徵維度為 2238=96,HOF 特徵和 MBH 特徵計算類似。
提取出 HOG 等資訊後,接下來具體的分類,與上面基於時空關鍵點的方法類似,不再贅述。
4 深度學習方法
當前基於 CNN 的方法不需要手動提取特徵,性能已經完全超越傳統方法,以 3D 卷積,RNN/LSTM 時序模型,雙流法等模型為代表。
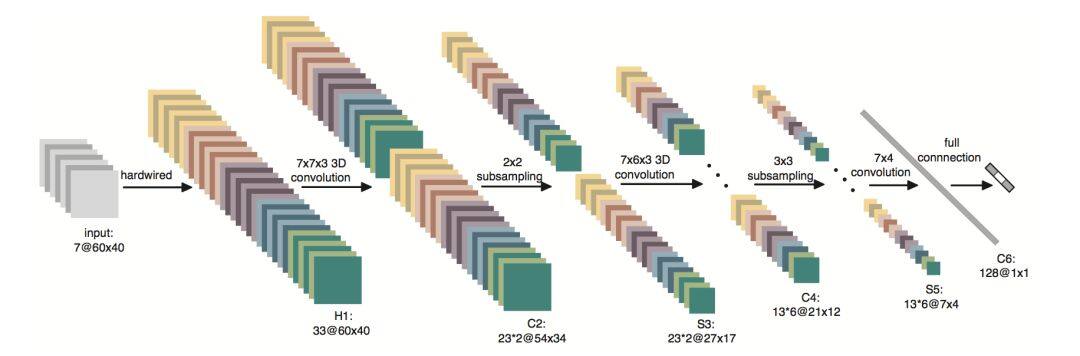
4.1 3D 卷積
影像相對於圖像多出了一個維度,而 3D 卷積正好可以用於處理這個維度,因此也非常適合影像分類任務,缺點是計算量比較大,下圖展示了一個簡單的 3D 模型。
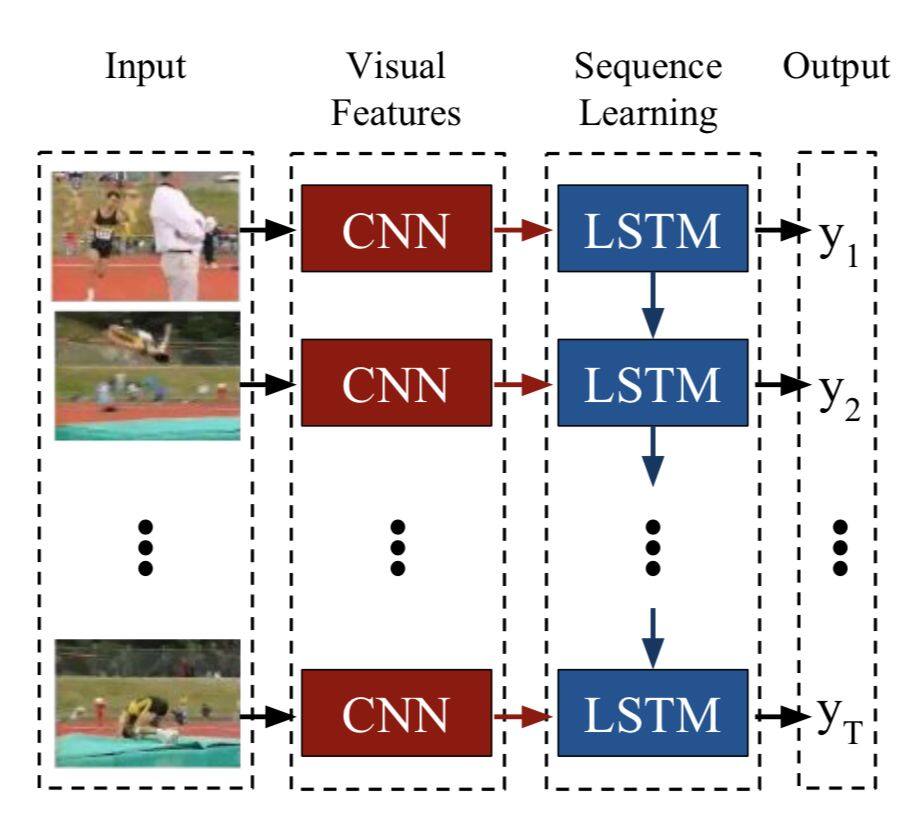
4.2 RNN/LSTM
視訊和語音信號都是時序信號,而 RNN 和 LSTM 正是處理時序信號的模型。如下圖所示,透過 CNN 對每一個影像幀提取特徵,使用 LSTM 建模時序關係。
4.3 雙流法 (two-stream)
雙流法包含兩個通道,一個是 RGB 圖像通道,用於建模空間資訊。一個是光流通道,用於建模時序資訊。兩者聯合訓練,並進行資訊融合。
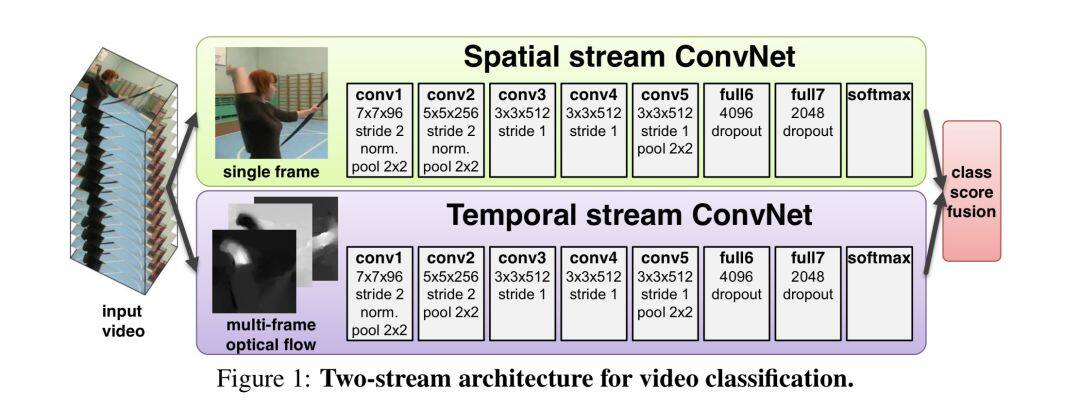
雙流模型是影像分類中非常重要的一類模型,在特徵的融合方式,光流的提取等方向,都有非常多的研究,關於更多模型的解讀如果感興趣,可以移步有三 AI 知識星球中的模型結構 1000 變板塊。

4.4 其他
關於各種影像分類的網路結構解讀,有興趣的同學可以到有三 AI 知識星球中,進行閱讀和後續學習。
5 總結
雖然在 UCF-101 數據集上評測指標,已經達到了 98.5%,但是影像的分類目前遠沒有圖像分類成熟,面臨著巨大的類內方差,相機運動和背景干擾,數據不足等難題。
除了要解決以上難題外,有以下幾個重要方向是值得研究的。
- 多模態資訊融合。即不只是採用圖像信息,還可以融合語音等資訊。
- 多標籤影像分類。與多標籤圖像分類類似,現實生活中的影像可能有多個標籤。
- 行為定位。一段影像中的行為有開始和結束,如何定位到真正有效的片段,是之後的影像分類的重要前提。
- 參考文獻
- [1] Kong Y, Fu Y. Human action recognition and prediction: A survey[J]. arXiv preprint arXiv:1806.11230, 2018.[2] Laptev I. On space-time interest points[J]. International journal of computer vision, 2005, 64(2-3): 107-123.[3] Scovanner P, Ali S, Shah M. A 3-dimensional sift descriptor and its application to action recognition[C]//Proceedings of the 15th ACM international conference on Multimedia. ACM, 2007: 357-360.[4] Wang H, Kläser A, Schmid C, et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International journal of computer vision, 2013, 103(1): 60-79.[5] Ji S, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2012, 35(1): 221-231.[6] Donahue J, Anne Hendricks L, Guadarrama S, et al. Long-term recurrent convolutional networks for visual recognition and description[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 2625-2634.[7] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]//Advances in neural information processing systems. 2014: 568-576.作者介绍
言有三,真名龍鵬,曾先後就職於奇虎 360AI 研究院、陌陌深度學習實驗室,6 年多電腦視覺從業經驗,擁有豐富的傳統圖像算法,和深度學習圖像項目經驗,擁有技術公眾號《有三 AI》,著有書籍《深度學習之圖像識別:核心技術與案例實戰》。原文鏈接

0 comments:
張貼留言