MICRO EXPRESSIONS in 4K - LIE TO ME Style Analysis - Micro Expressions Training like in Lie To Me


隨著機器學習和深度神經網路,兩個領域的迅速發展,以及智慧設備的普及,人臉辨識技術正在經歷前所未有的發展,關於人臉辨識技術討論從未停歇。目前,人臉辨識精度已經超過人眼,同時大規模普及的軟硬體基礎條件也已具備,應用市場和領域需求很大,基於這項技術的市場發展和具體應用,正呈現蓬勃發展態勢。人臉表情辨識 (facial expression recognition, FER) 作為人臉辨識技術中的一個重要組成部分,近年來在人機交互、安全、機器人製造、自動化、醫療、通信和駕駛領域,得到了廣泛的關注,成為學術界和工業界的研究熱點。本文將對人臉辨識中的表情辨識的相關內容,做一個較為詳細的綜述。
1 表情相關概述
1.1 表情定義與分類
「表情」是我們日常生活中,提到很多的一個詞語,在人際溝通中,人們透過控制自己的臉部表情,可以加強溝通效果。人臉表情是傳播人類情感資訊,與協調人際關係的重要方式,據心理學家 A.Mehrabia 的研究顯示,在人類的日常交流中,透過語言傳遞的資訊,僅佔資訊總量的 7%,而透過人臉表情傳遞的資訊,卻達到資訊總量的 55%,可以這麼說,我們每天都在對外展示自己的表情,也在接收別人的表情,那麼表情是什麼呢?
臉部表情,是臉部肌肉的一個或多個動作或狀態的結果。這些運動表達了個體對觀察者的情緒狀態。臉部表情是非語言交際的一種形式。它是表達人類之間的,社會資訊的主要手段,不過也發生在大多數其他哺乳動物,和其他一些動物物種中。
人類的臉部表情至少有 21 種,除了常見的高興、吃驚、悲傷、憤怒、厭惡和恐懼 6 種,還有驚喜(高興+吃驚)、悲憤(悲傷+憤怒)等 15 種可被區分的復合表情。
表情是人類及其他動物,從身體外觀投射出的情緒指標,多數指臉部肌肉,及五官形成的狀態,如笑容、怒目等。也包括身體整體表達出的身體語言。一些表情可以準確解釋,甚至在不同物種成員之間,憤怒和極端滿足是主要的例子。
然而,一些表情則難以解釋,甚至在熟悉的個體之間,厭惡和恐懼是主要的例子。一般來說,臉部各個器官是一個有機整體,協調一致地表達出同一種情感。
臉部表情是人體(形體)語言的一部分,是一種生理及心理的反應,通常用於傳遞情感。
1.2 表情的研究
臉部表情的研究始於 19 世紀,1872 年,達爾文在他著名的論著《人類和動物的表情(The Expression of the Emotions in Animals and Man,1872)》中,就闡述了人的臉部表情,和動物的臉部表情之間的聯繫和區別。
1971 年,Ekman 和 Friesen 對現代人臉表情辨識,做了開創性的工作,他們研究了人類的 6 種基本表情(即高興、悲傷、驚訝、恐懼、憤怒、厭惡),確定辨識對象的類別,並系統地建立了有上千幅,不同表情的人臉表情圖像數據庫,細緻的描述了每一種表情,所對應的臉部變化,包括眉毛、眼睛、眼瞼、嘴唇等等是如何變化的。
1978 年,Suwa 等人對一段人臉影像動畫,進行了人臉表情辨識的最初嘗試,提出了在圖像序列中,進行臉部表情自動分析。
20 世紀 90 年代開始,由 K.Mase 和 A.Pentland 使用光流,來判斷肌肉運動的主要方向,使用提出的光流法,進行臉部表情辨識之後,自動臉部表情辨識,進入了新的時期。
1.3 微表情
隨著對表情研究的深入,學者們將目光聚焦到,一種更加細微的表情的研究,即微表情的研究,那麼什麼是微表情呢?
微表情是心理學名詞,是一種人類在試圖隱藏某種情感時,無意識做出的、短暫的臉部表情。他們對應著七種世界通用的情感:厭惡、憤怒、恐懼、悲傷、快樂、驚訝和輕蔑。微表情的持續時間,僅為 1/25 秒至 1/5 秒,表達的是一個人試圖壓抑與隱藏的真正情感。雖然一個下意識的表情,可能只持續一瞬間,但有時表達相反的情緒。
微表情具有巨大的商業價值和社會意義。
在美國,針對微表情的研究,已經應用到國家安全、司法系統、醫學臨床和政治選舉等領域。在國家安全領域,有些訓練有素的恐怖分子等危險人物,可能輕易就透過測謊機的檢測,但是透過微表情,一般就可以發現他們,虛假表面下的真實表情,並且因為微表情的這種特點,它在司法系統和醫學臨床上,也有著較好的應用。
電影製片人導演或者廣告製作人等,也可以透過人群抽樣採集的方法,對他們觀看宣傳片,或者廣告時候的微表情,來預測宣傳片或者廣告的收益如何。
總之,隨著科技的進步和心理學的不斷發展,對臉部表情的研究,將會越來越深入,內容也會越來越豐富,應用也將越來越廣泛。
2 表情辨識的應用
2.1 線上 API(Application Programming Interface《應用程式介面》)
(1) Microsoft Azure
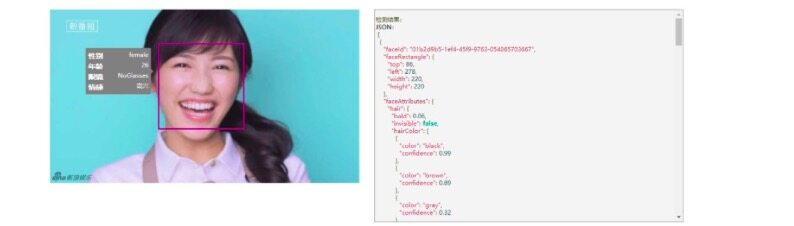
該 API 包括人臉驗證、臉部檢測、以及表情辨識等幾部分。對於人臉 API 已整合的表情辨識功能,可針對圖像上所有臉部的一系列表情(如氣憤、蔑視、厭惡、恐懼、高興、沒有情緒、悲傷和驚訝)返回置信度,透過 JSON 返回辨識結果。可以認為這些情感,跨越了文化界限,通常由特定的臉部表情傳達。
圖 2.1 為人臉 API 辨識結果:
(2) Baidu AI 開放平台(配備微信小程式)
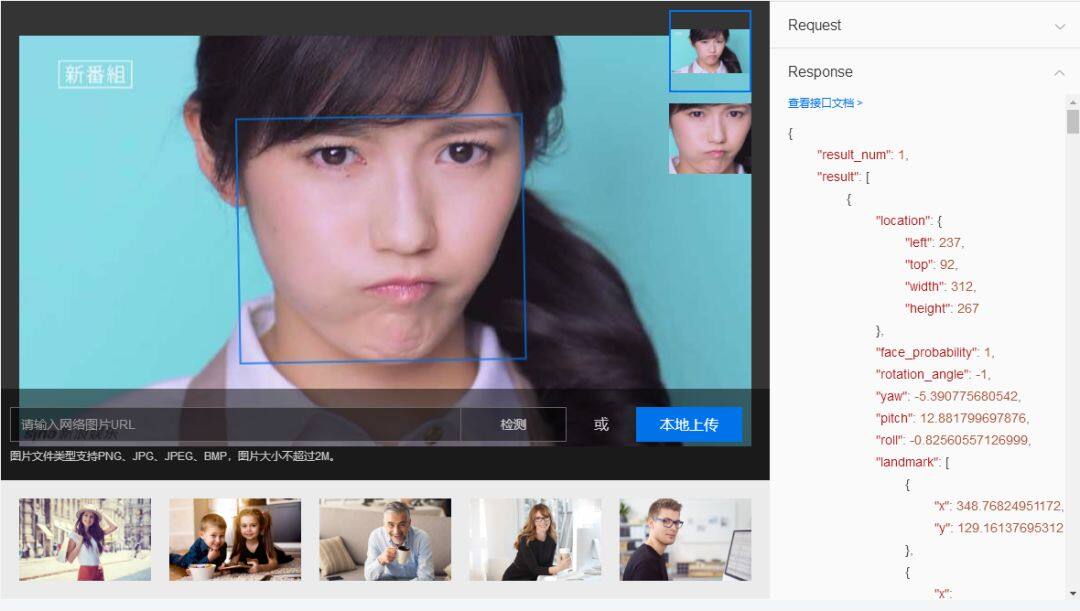
該 API 可以檢測圖中的人臉,並為人臉標記出邊框。檢測出人臉後,可對人臉進行分析,獲得眼、口、鼻輪廓等 72 個關鍵點定位,準確辨識多種人臉屬性,如性別,年齡,表情等資訊。該技術可適應大角度側臉,遮擋,模糊,表情變化等各種實際環境。
鏈接: https://ai.baidu.com/tech/face/detect
圖 2.2 為該 API 的功能演示。
(3) 騰訊優圖 AI 開放平台(配備微信小程式)
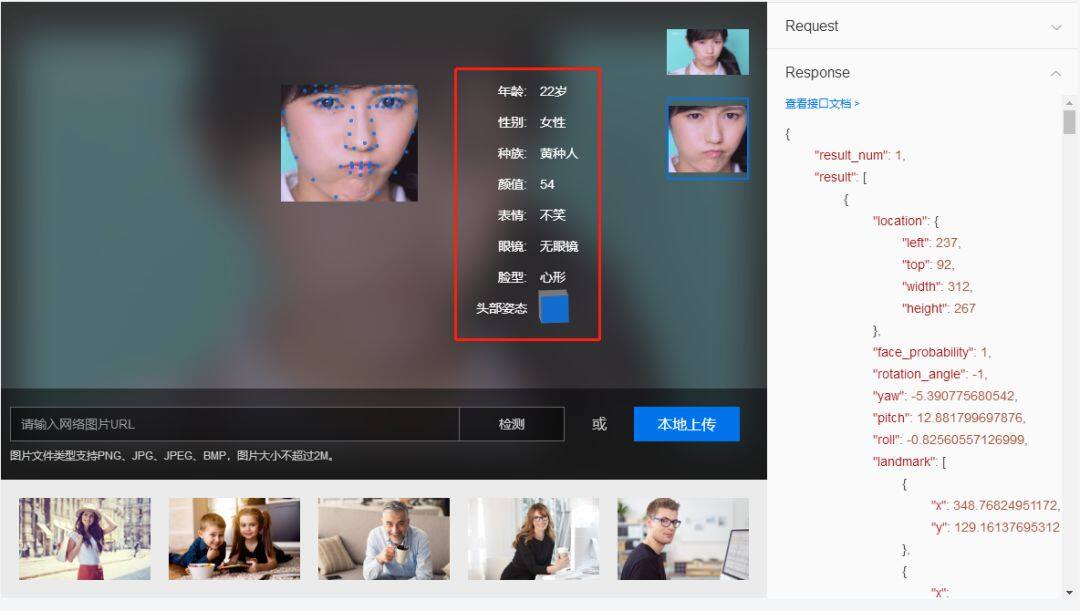
該 API 對於任意一幅給定的圖像,採用智慧策略對其進行搜索,以確定其中是否含有人臉,如果是,則返回人臉的位置、大小和屬性分析結果。當前支持的人臉屬性有:性別、表情(中性、微笑、大笑)、年齡(誤差估計小於 5 歲)、是否佩戴眼鏡(普通眼鏡、墨鏡)、是否佩戴帽子、是否佩戴口罩。
目前優圖人臉檢測和分析,不僅成熟應用於圖片內的人臉顏值分析,檢測到人臉時啓動相機等娛樂場景,還可透過對圖像或影像中的人臉,進行檢測和計數,能夠輕鬆瞭解區域內的人流量,並且可以透過對廣告受眾群體的人臉檢測和分析,瞭解人群的性別、年齡等屬性和分布,據此進行更精準對應的廣告投放。
圖 2.3 為該 API 的功能演示。


2.2 APP
(1) Polygram
Line、微信等社群工具,已經成為了我們生活中,必不可少的一部分,社交、轉賬、支付、購物。在中國,微信已成為一個載體,刷微信、刷朋友圈、發段子、鬥圖,成為了中國人民空閒時間的日常,各種微信表情包成為一大主流。
Polygram 與以往的社交軟體的方式不同,是一款基於人臉辨識的表情包,為主要特色的社交軟體,加持人臉辨識與神經網路技術,它可以使用者的臉部表情,來生成一個 emoji。在這裡,用戶可以透過人臉辨識技術,搜索發送相應表情。
Polygram 是一個人工智慧動力社會網路,可以理解人臉表情。它以基於人臉辨識的表情包為主要特色,即能夠利用人臉辨識技術,對面部的真實表情進行檢測,從而搜索到相應的表情,併發送該表情。
當使用者在 Polygram 上發佈圖片或影片時,它非常聰明的是可以使用臉部辨識技術和手機攝影機,自動捕獲使用者在社交平台上,瀏覽朋友分享的照片、文字、影片等資訊時,臉部出現的真實表情,您將瞭解您的好友對他們的感受。
這是透過模仿臉部表情的,現場表情符號來完成的,並允許用戶對自己的臉部做出反應。

(2) 落網 emo
emo,是一款可以辨識情緒的音樂 APP,我們總是在掏出手機,打開音樂播放器之後,不停的在播放列表中找歌,卻難以在存了幾百首歌的播放列表中,找到此刻想聽的,這並非出於執念,只是因為心情。快樂的時候,想聽跳躍的歌;悲傷的時候,要放低沈的曲兒;激動的時候,需要激昂的調……每個人都有心情不同的時候,每個人都需要不同的音樂解藥。emo 因此而生,解決聽歌煩惱,在最適合的時候播放最適合的歌。
在 emo 面前的你,會是最誠實的你,不必掩藏你的心情,愉快便是愉快,悲傷即是悲傷。emo 會通過前置攝影機掃描你的臉,推算出你當下的心情狀態,你會驚訝於它的準確度之高,而且,不僅是愉快悲傷,它還能「看」出來其它心情如:平靜、困惑、驚訝、憤怒等等。
推算心情不是唯一讓人驚嘆的地方,在推算出你的心情狀態之後,emo 還會貼心地為你推送音樂。emo 擁有龐大優質的音樂後台曲庫,推送的每一首歌,都由人工打上心情標籤,每一首歌都是我們為你精心挑選的,符合你現時心情的。
簡單來說 emo 是一個音樂播放器,而臉部辨識技術的嵌入,讓這個播放器又沒那麼簡單 —— emo 可以透過掃描使用者的臉部表情,判斷使用者的情緒,推薦給使用者相應的音樂。產品的立意是希望使用者在每一刻,都能聽到想聽的符合心情的歌曲。總體而言,該 App 也跳出了一般意義上的播放器,是一款十分有意思的產品,期待優化的更好一些。其他三大主流音樂播放器,或許未來也可以借鑒一下。
2.3 分析總結
目前,各家大廠的 API 都已經非常成熟,同時由於微信小程式的興起,很多 APP 的功能,都可以遷移至小程式完成,透過廣泛的調研,可以發現目前做人臉辨識的產品較多,而聚焦於表情辨識的並不多,或者僅僅是簡單的給出,是否微笑等簡單的表情提示,大部分並沒有將其與產品進行一個有機的結合。在調研過程中,個人覺得 emo 是一個很好的點子,不過很可惜並沒有得到很好的推廣。
目前,僅針對人臉辨識的技術相對成熟,表情辨識還有很大的市場,接下來需要做的是將表情辨識運用到實際場景中,將其與現實需求進行良好結合。例如在遊戲的製作上面,可以根據人類情感做出即時反映,增強玩家沈浸感;
在遠端教育方面,可以根據學生表情調整授課進度、授課方法等;在安全駕駛方面,可以根據司機表情,判斷司機駕駛狀態,避免事故發生。
在公共安全監控方面,可以根據表情,判斷是否有異常情緒,預防犯罪;在製作廣告片的時候,製作者往往都會頭疼一個問題:該在什麼時候插入商標 logo、該在什麼時候跳出產品圖片,才能讓觀眾對這個品牌、這個產品有更深的印象?
表情辨識就可以幫助廣告製作者,解決這一令人頭疼的問題。製作者只需要在廣告片完成後,邀請一部分人來試看這個廣告片,並在試看過程中,使用表情辨識系統測試,觀看者的情緒變化,找到他們情緒波動最大的段落,這就是最佳的 logo 插入段落。
與其類似的,可以幫助廣告製作者,找出最佳的 logo 植入點,還可以幫助電影製作方,尋找出一部電影中,最吸引人的部分來製作電影的預告片,以確保預告片足夠吸引人,保證有更多的人在看完預告片後,願意走進電影院觀看「正片」。
表情辨識是一個很有發展前景的方向,將其與日常所需緊密聯繫,是這類產品需要考量的重要因素,而不單單只是給一個檢測結果而已,或許這個未來的發展方向之一。
3 表情常用開源數據庫
(1) KDEF 與 AKDEF(karolinska directed emotional faces) 數據集
這個數據集最初是被開發,用於心理和醫學研究目的。它主要用於知覺、注意、情緒、記憶等實驗。在創建數據集的過程中,特意使用比較均勻,柔和的光照,被採集者身穿統一的 T 恤顏色。這個數據集,包含 70 個人,35 個男性,35 個女性,年齡在 20 至 30 歲之間。
沒有鬍鬚,耳環或眼鏡,且沒有明顯的化妝。7 種不同的表情,每個表情有 5 個角度。總共 4900 張彩色圖。尺寸為 562 * 762 像素。圖 3.1 是該數據集中一個微笑的示例。
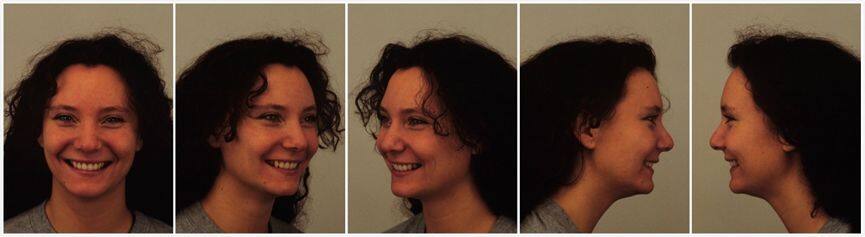
(2) RaFD 數據集
該數據集是 Radboud 大學 Nijmegen 行為科學研究所整理的,這是一個高品質的臉部數據庫,總共包含 67 個模特兒:20 名白人男性成年人,19 名白人女性成年人,4 個白人男孩,6 個白人女孩,18 名摩洛哥男性成年人。
總共 8040 張圖,包含 8 種表情,即憤怒、厭惡、恐懼、快樂、悲傷、驚奇、蔑視和中立。每一個表情,包含 3 個不同的注視方向,且使用 5 個相機從不同的角度同時拍攝的,圖 3.2 是該數據集中 5 個方向的一個示例,圖 3.3 是該數據集中一個表情的示例。


(3) Fer2013 數據集
該數據集,包含共 26190 張 48*48 灰度圖,圖片的解析度比較低,共 6 種表情。分別為 0 anger 生氣、1 disgust 厭惡、2 fear 恐懼、3 happy 開心、4 sad 傷心、5 surprised 驚訝、6 normal 中性。圖 3.4 為 Fer2013 數據集的部分數據。

圖 3.4 Fer2013 Database 的部分數據
(4) CelebFaces Attributes Dataset (CelebA) 數據集
CelebA 是商湯科技的,一個用於研究人臉屬性的數據集,一個包含超過 200K 名人圖像的大型人臉屬性數據集,每個數據集都有 40 個屬性注釋。
該數據集中的圖像涵蓋了大型姿態變化和複雜背景。CelebA 的多樣非常好,有約 10 萬張帶微笑屬性的數據,圖 3.5 是該數據集中一些微笑的示例。

(5) Surveillance Cameras Face Database(SCface)
鏈接: http://www.scface.org/
SCface 是人臉靜態圖像的數據庫。圖像是在不受控制的室內環境中,使用五種不同品質的影像監控攝影機拍攝的。數據庫包含 130 個主題的 4160 靜態圖像(在可見和紅外線光譜中)。圖 3.6 是該數據集中不同姿勢的一些示例。

(6) Japanese Female Facial Expression (JAFFE) Database
該數據庫包含由 10 名日本女性模特兒,組成的 7 幅臉部表情(6 個基本臉部表情 +1 個中性)的 213 幅圖像。每個圖像被 60 個日語科目評為 6 個情感形容詞。圖 3.7 是該數據集中的部分數據。
圖 3.7 JAFFE 中的部分數據
除上述介紹到的開源數據集外,還有許多關於表情的開源數據集,總之需要多去搜索總結,使用這些開源數據集,我們可以省去很多構造數據的時間,也便於我們訓練出一個強健性(Robustness)比較好的模型。
4 人臉表情辨識研究方法
4.1 表情辨識系統
人臉表情辨識系統如圖 4.1 所示,主要由人臉圖像的獲取、人臉檢測、特徵提取、特徵分類四部分組成。

圖 4.1 人臉表情辨識系統
由於開源表情數據庫目前已經比較多,圖像獲取難度不大,人臉檢測算法也比較成熟,已經發展成為一個獨立的研究方向,因此人臉表情辨識的研究,主要體現在系統的後面兩個步驟:特徵提取和特徵分類上,下面將從傳統研究方法,和深度學習研究方法,對以上兩個步驟進行闡述。
4.2 傳統研究方法
4.2.1 特徵提取
表情特徵提取主要採用數學方法,依靠電腦技術對人臉表情的數位圖像,進行數據的組織和處理,提取表情特徵,去除非表情噪聲的方法。在某些情況下,特徵提取算法提取了圖像的主要特徵,客觀上降低了圖像的維數,因此這些特徵提取算法,也具有降維的作用。
人臉表情的產生是一個很複雜的過程,如果不考慮心理和環境因素,呈現在觀察者面前的,就是單純的肌肉運動,以及由此帶來的臉部形體和紋理的變化。靜態圖像呈現的,是表情發生時單幅圖像的表情狀態;動態圖像呈現的,是表情在多幅圖像之間的運動過程。
因此根據表情發生時的狀態,和處理對象來區分,表情特徵提取算法,大體分為基於靜態圖像的特徵提取方法,和基於動態圖像的特徵提取方法。
其中基於靜態圖像的特徵提取算法,可分為整體法和局部法,基於動態圖像的特徵提取算法,又分為光流法、模型法和幾何法。
基於靜態圖像的特徵提取方法:
(1)整體法
人臉表情依靠肌肉的運動來體現。人臉表情靜態圖像直接地顯示了,表情發生時人臉肌肉運動,所產生的臉部形體和紋理的變化。從整體上看,這種變化造成了臉部器官的明顯形變,會對人臉圖像的全局資訊帶來影響,因此出現了從整體角度,考慮表情特徵的人臉表情辨識算法。
整體法中的經典算法,包括主元分析法(PCA)、獨立分量分析法(ICA)和線性判別分析法(LDA)。研究者針對於此也做了大量的工作,採用 Fast ICA 算法提取表情特徵,該方法不但繼承了 ICA 算法,能夠提取像素間隱藏資訊的特點,而且可以透過更新,快速地完成對表情特徵的分離。
支持向量鑒別分析(SVDA)算法,該算法以 Fisher 線性判別分析,和支援向量機基礎,能夠在小樣本數據情況下,使表情數據具有最大的類間分離性,而且不需要構建 SVM 算法所需要的決策函數。實驗證明瞭該算法的辨識率,高於 PCA 和 LDA。
依靠 2D 離散餘弦變換,透過頻域空間對人臉圖像進行映射,結合神經網路,實現對表情特徵的分類。
(2)局部法
靜態圖像上的人臉表情,不僅有整體的變化,也存在局部的變化。臉部肌肉的紋理、皺摺等局部形變所蘊含的資訊,有助於精確地判斷表情的屬性。局部法的經典方法是 Gabor 小波法和 LBP 算子法。
以 Gabor 小波等多種特徵提取算法為手段,結合新的分類器對靜態圖像展開實驗。
首先人工標記了 34 個人臉特徵點,然後將特徵點的 Gabor 小波系數,表示成標記圖向量,最後計算標記圖向量,和表情語義向量之間的 KCCA 系數,以此實現對表情的分類。
CBP 算子法,透過比較環形鄰域的近鄰點對,降低了直方圖的維數。針對符號函數的修改,又增強了算法的抗噪性,使 CBP 算子法取得了較高的辨識率。
基於動態圖像的特徵提取方法:
動態圖像與靜態圖像的不同之處在於:動態圖像反映了人臉表情發生的過程。因此動態圖像的表情特徵,主要表現在人臉的持續形變,和臉部不同區域的肌肉運動上。
目前基於動態圖像的特徵提取方法,主要分為光流法、模型法和幾何法。
(1)光流法
光流法是反映動態圖像中,不同幀之間相應物體灰度變化的方法。早期的人臉表情辨識算法多採用光流法,提取動態圖像的表情特徵,這主要在於光流法,具有突出人臉形變、反映人臉運動趨勢的優點。因此該算法依舊是傳統方法中,來研究動態圖像表情辨識的重要方法。
首先採用連續幀之間的光流場和梯度場,分別表示圖像的時空變化,實現每幀人臉圖像的表情區域跟蹤;然後透過特徵區域運動方向的變化,表示人臉肌肉的運動,進而對應不同的表情。
(2)模型法
人臉表情辨識中的模型法,是指對動態圖像的表情資訊,進行參數化描述的統計方法。常用算法主要包括主動形狀模型法(ASM)和主動外觀模型法(AAM),兩種算法都可分為形狀模型和主觀模型兩部分。
就表觀模型而言,ASM 反映的是圖像的局部紋理資訊,而 AAM 反映的是圖像的全局紋理資訊。提出了基於 ASM 的 3D 人臉特徵跟蹤方法,該方法對人臉 81 個特徵點,進行跟蹤建模,實現了對部分複合動作單元的辨識。
借助圖像的地形特徵模型,來辨識人臉動作和表情;利用 AAM 和人工標記的方法,跟蹤人臉特徵點,並按照特徵點取得人臉表情區域;透過計算人臉表情區域的地形直方圖,來獲得地形特徵,從而實現表情辨識。
基於 2D 表觀特徵和 3D 形狀特徵的 AAM 算法,在人臉位置發生偏移的環境下,實現了對表情特徵的提取。
(3)幾何法
在表情特徵提取方法中,研究者考慮到表情的產生與表達,在很大程度上,是依靠臉部器官的變化來反映的。人臉的主要器官及其褶皺部分,都會成為表情特徵集中的區域。
因此在臉部器官區域標記特徵點,計算特徵點之間的距離,和特徵點所在曲線的曲率,就成為了採用幾何形式提取人臉表情的方法。
使用形變網格對不同表情的人臉進行網格化表示,將第一幀與該序列表情,最大幀之間的網格節點,坐標變化作為幾何特徵,實現對表情的辨識。
4.2.2 特徵分類
特徵分類的目的,是判斷特徵所對應的表情類別。在人臉表情辨識中,表情的類別分為兩部分:基本表情和動作單元。前者一般適用於所有的處理對象,後者主要適用於動態圖像,可以將主要的特徵分類方法,分為基於貝葉斯網路的分類方法,和基於距離度量的分類方法。
(1)基於貝葉斯網路的分類方法
貝葉斯網路是以貝葉斯公式為基礎、基於概率推理的圖形化網路。從人臉表情辨識的角度出發,概率推理的作用,就是從已知表情資訊中,推斷出未知表情的機率資訊的過程。基於貝葉斯網路的方法,包括各種貝葉斯網路分類算法,和隱馬爾科夫模型(HMM)算法。
研究者分別採用了樸素貝葉斯(NB)分類器、樹增強器(TAN)和 HMM 實現表情特徵分類。
(2)基於距離度量的分類方法
基於距離度量的分類方法,是透過計算樣本之間的距離,來實現表情分類的。代表算法有近鄰法和 SVM 算法。近鄰法是比較未知樣本 x ,與所有已知類別的樣本之間的歐式距離,透過距離的遠近,來決策 x 與已知樣本是否同類;SVM 算法則是透過優化目標函數,尋找到使不同類別樣本之間,距離最大的分類超平面。
採用了最近鄰法對表情特徵進行分類,並指出最近鄰法的不足之處,在於分類正確率的大小,依賴於待分類樣本的數量。分別從各自角度提出了對 SVM 的改進,前者將 k 近鄰法與 SVM 結合起來,把近鄰資訊整合到 SVM 的構建中,提出了局部 SVM 分類器;後者提出的 CSVMT 模型,將 SVM 和樹型模組結合起來,以較低的算法複雜度,解決了分類子問題。
4.3 深度學習方法
上述均為傳統研究方法的一些介紹,下文主要講述,如何將深度學習應用到表情辨識裡,並將以幾篇文章為例,來詳細介紹一下,現在深度學習方法的研究方法和思路。
與傳統方法特徵提取不同,之所以採用深度學習的方法,是因為深度學習中的網路(尤其是 CNN)對圖像具有較好的提取特徵的能力,從而避免了人工提取特徵的繁瑣,人臉的人工特徵,包括常用的 68 個 Facial landmarks 等其他的特徵,而深度學習除了預測外,往往還扮演著特徵工程的角色,從而省去了人工提取特徵的步驟。
下文首先介紹深度學習中,常用的網路類型,然後介紹透過預訓練的網路,對圖像進行特徵提取,以及對預訓練的網路,採用自己的數據進行微調的 Fine-Tunning。
如果將深度學習中,常用的網路層 CNN、RNN、Fully-Connect 等層組合成網路,將會產生多種選擇,然而這些網路性能的好與壞,需要更多地探討,經過很多研究者的一系列實踐,很多網路模型已經具備很多的性能,如 ImgeNet 比賽中提出模型: AlexNet、GoogleNet(Inception)、 VGG、ResNet 等。這些網路已經經過了 ImageNet 這個強大數據集的考驗,因此在圖像分類問題中也常被採用。
對於網路的結構,往往是先透過若干層 CNN,進行圖像特徵的提取,然後透過全連接層,進行非線性分類,這時的全連接層就類似與 MLP,只是還加入了 Dropout 等機制防止過擬合等,最後一層有幾個分類,就連接幾個神經元,並且透過 Softmax 變換得到,樣本屬於各個分類的機率分布。
關於人臉表情辨識的討論一直在繼續,很多學者團隊都聚焦於此。
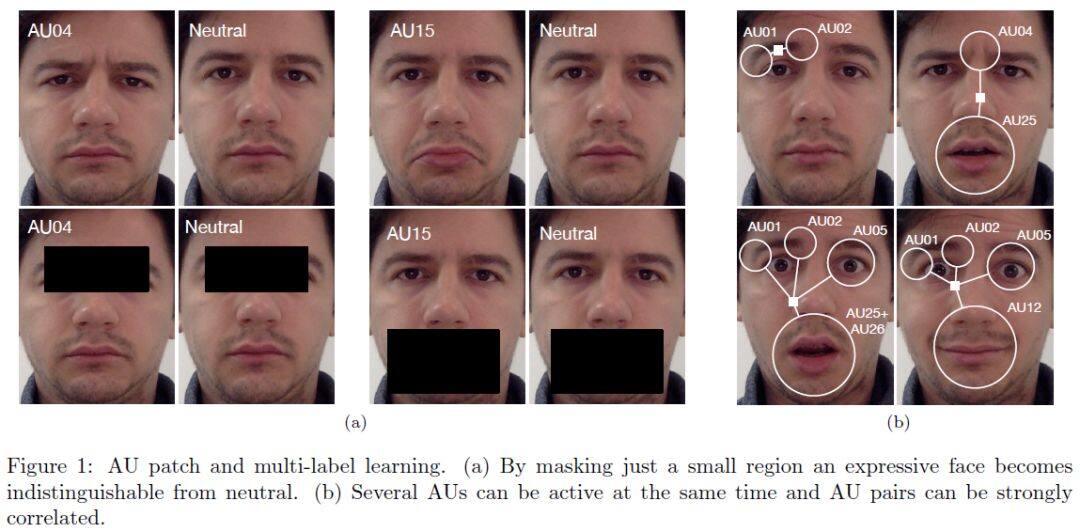
用於注釋自然情緒臉部表情的,一百萬個圖像的大型數據庫(即,從因特網下載的臉部圖像)。首先,證明這個新提出的算法,可以跨數據庫可靠地辨識 AU 及其強度。根據調研,這是第一個在多個數據庫中,辨識 AU 及其強度的高精度結果的已發佈算法。
算法可以即時運行(> 30 張圖像 / 秒),允許它處理大量圖像和影像序列。其次,使用 WordNet 從網路下載 1,000,000 張臉部表情圖像,以及相關的情感關鍵詞。
然後透過我們的算法用 AU、AU 強度,和情感類別自動注釋這些圖像。可以得到一個非常有用的數據庫,可以使用語義描述,輕鬆查詢電腦視覺、情感計算、社會和認知心理學,和神經科學中的應用程式。

還有一種深度神經體系結構,它透過在初始階段,結合學習的局部和全局特徵,來解決這兩個問題,並在類之間複製消息傳遞算法,類似於後期階段的圖形模型推理方法。
結果顯示,透過增加對端到端訓練模型的監督,在現有水準的基礎上,我們分別在 BP4D 和 DISFA 數據集上,提高了 5.3%和 8.2%的技術水準。

0 comments:
張貼留言