How to Build a Custom YOLOv4 Object Detector using TensorFlow (LP Detector)
如何使用TensorFlow(牌照檢測器)構建自定義YOLOv4對象檢測器

先說好,我們今天辨識的不是這種車牌↓↓↓

本教程將簡單講解,如何在 15 分鐘內用深度學習,搭建一個現代的文字辨識系統,主要是教你如何使用 Keras 和 Supervisely,來解決文字辨識問題的主要原理。任何想學習用深度學習技術,辨識圖像中文字,但又毫無頭緒的人,都應該參考本篇指南。

文字辨識在現實世界中,有一個簡單的應用:車牌號辨識。車牌號辨識是一個非常好的入門實例,並且你能夠根據自己的問題,進行針對性的調整。今天我們就來看看如何用 Keras 和 Supervisely 辨識出車牌號。
在深入這一領域時,我們面臨的首要問題,就是網路上缺少足夠的資料和資源。經過長期的研究,並閱讀了大量的論文後,我們終於對如何創建一套有效的辨識系統,確立了一些主要理念同時,我們在下面兩段影片中(part1 和 part2),以通俗易懂的方式,分享了我們自己的理解和觀點。
我們認為其中的內容非常有價值,它簡單而又有效地解釋了,如何構建現代化的辨識系統,這是非常難能可貴的。因此我們強烈建議你先觀看一下這些影片,它們能夠帶給你許多解決辨識問題的直觀認識。
影片 Part2 超過 15 分鐘被編輯器限制了,傳送:
為了萬無一失地學習本教程,你需要準備好 Ubuntu 操作系統、GPU 和 Docker。
本文中所有的資源,都可以在 github 上獲取,源代碼以及注釋和可視化資訊,都儲存在一個單獨的 jupyther 筆電中。(資源地址見文末)
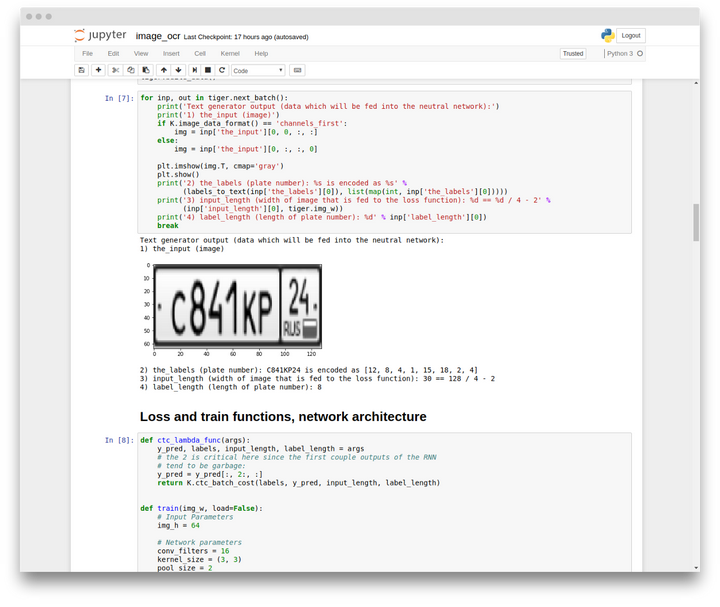
哪裡能夠獲取訓練數據?
針對這篇教程,我們生成了 10K 以上的與真實車牌號相似的人工數據集,它們的樣子是這樣的:
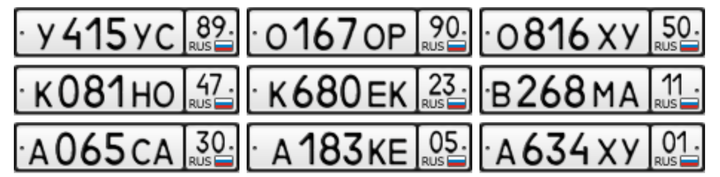
透過 Supervisely,你可以方便的得到這份數據集。關於這份數據集,我們在 DeepSystems 中做了大量的電腦視覺方面的開發工作,比如自主駕駛汽車、發票辨識系統、道路缺陷探測等,針對訓練數據,數據科學家花費了大量時間,做了大量工作,包括創建特殊的圖像注釋,將數據與公開的數據集合併,進行數據擴展等。
Supervisely 簡化了使用數據集的工作,並能自動完成許多例行的任務,我們相信在日常工作中,你一定會發現它的用處和價值。
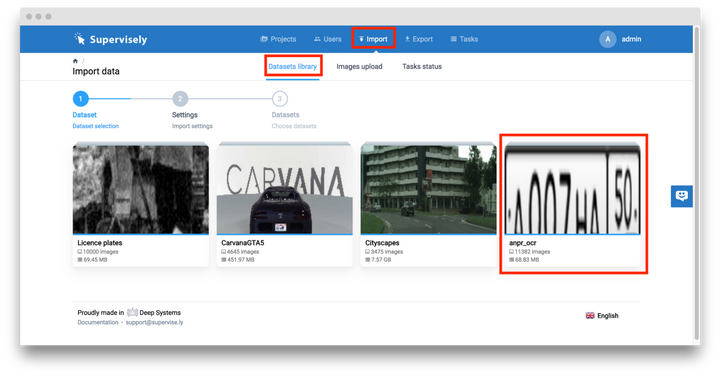
首先我們要在 Supervisely 上註冊賬戶 https://supervise.ly/ 完成註冊後依次點擊「Import」—> 「Datasets library」並選擇我們的「anpr_ocr」項目。
之後輸入項目名字 「anpr_ocr」 並點擊「Next」按鈕。
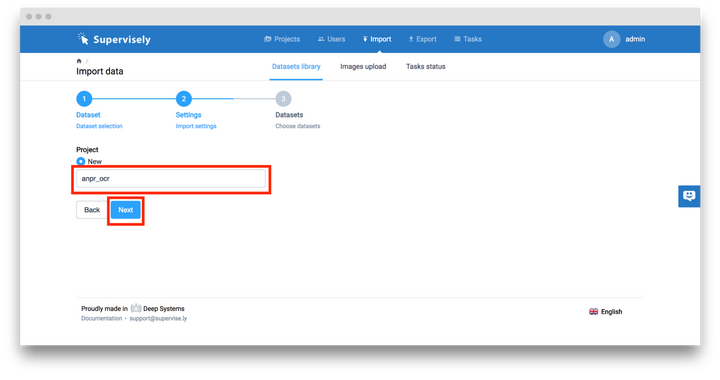
隨後點擊「Upload」按鈕。此時,項目「anpr_ocr」便完成創建並添加進了你的賬戶中。
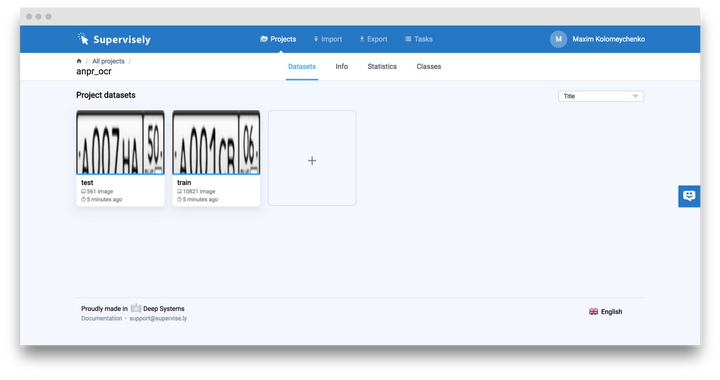
它有兩個數據集組成:「train」 和 「test」,即訓練集和測試集。
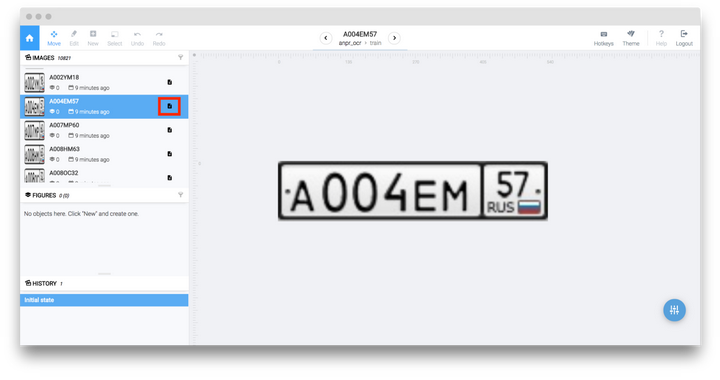
如果你想預覽圖片,只需點擊數據集即可,會馬上進入注釋工具。對於每一張圖片,我們都有一個描述性的文本,它將被作為真實的車牌號來訓練我們的系統。只需要點擊與所選擇的圖像相對的小標籤(標為紅色)就能夠瀏覽其內容。
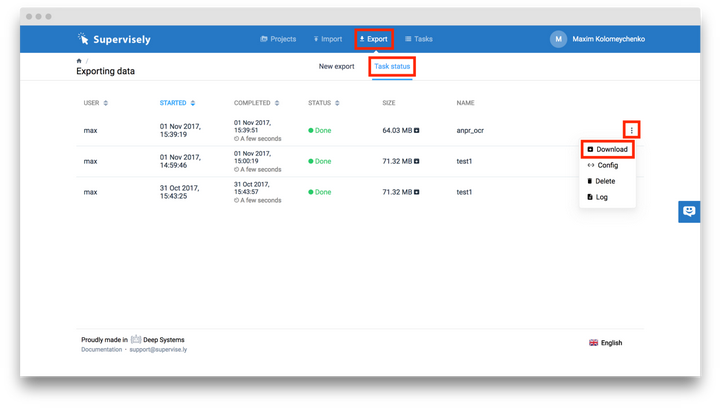
如果要下載數據集並保存為特定的格式,只需要點擊「Export」並輸入相應的配置資訊即可
如下所示:
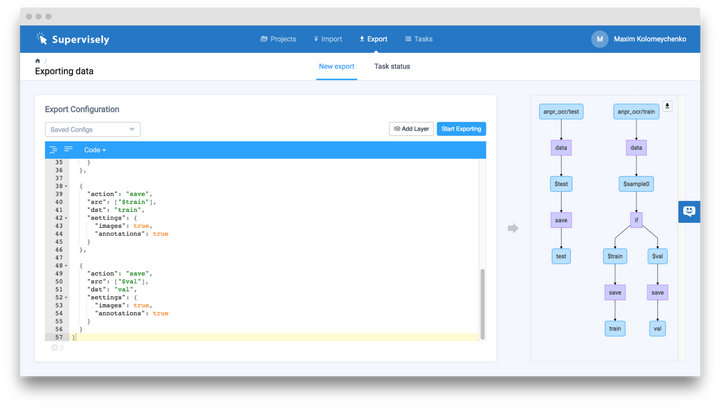
上面的截圖中對導出步驟進行了說明,此處不再贅述(可以閱讀網站文檔獲取更多資訊),我們重點關注下面的處理過程。在我們的「anpr_ocr」項目中,我們有兩個數據集,「Test」數據集與導出時相同,「Train」數據集被分成了兩部分:「train」 和 「val」,隨機選擇 95% 的圖片添加進「train」數據集中,剩下的 5% 則被加入「val」數據集中。
現在,你可以點擊「Start exporting」按鈕,稍等幾分鐘待系統完成文件打包等準備工作,隨後依次點擊「Export」 -> 「Task status」 -> 「Three vertical dots」 -> 「Download」按鈕即可下載訓練數據集(標為紅色)。
開始我們的實驗
在我們的 git 倉庫中,我們準備了所有需要的東西,透過下面的命令複製倉庫:
目錄結構如下所示:
將下載的 zip 打包文件放入 「data」 文件夾中並運行下面的命令:
在我們系統上,命令是這樣的:
現在我們結合預先配置好的環境(TensorFlow 和 Keras)來構建並運行 docker 容器,只需要進入「docker」文件夾並運行下面的命令:
在此之後你會進入容器中,運行下面的命令來啓動 Jupyther 筆電。
在終端中,你會看到類似下面這樣的資訊:

你必須將上面所選中的鏈接,複製粘貼到瀏覽器中,注意:你的鏈接和我的會略微不同。
最後一步是運行整個 「image_ocr.ipynb」 筆電,依次點擊「Cell」 -> 「Run all」。
筆電中包含以下幾個部分:數據加載和可視化、模型訓練、驗證集模型評估。這個數據訓練過程平均耗時約 30 分鐘。
如果一切順利,你將會看到像下面這樣的輸出結果:

如你所見,預測出的結果與真實值是相同的。就這樣,我們在一個非常簡潔的 jupyther 筆電上,建立了現代的 OCR 系統,在本文下面的章節中,我們將會解釋這個系統是如何工作的。
它是如何工作的?
對我們來說,理解神經網路架構是關鍵所在,不要吝惜 15 分鐘的時間,去看一看我們在開頭提到的影片吧,它提供了神經網路架構的上層概述,能夠讓你有一個基本的理解,如果你已觀看過它 —— 那就太好了:-)。
關於 CNN 和 LSTM 的講解,也可參閱集智主站的講解:


現在我會做一個簡短的解釋,隨後會有更高層次的說明。
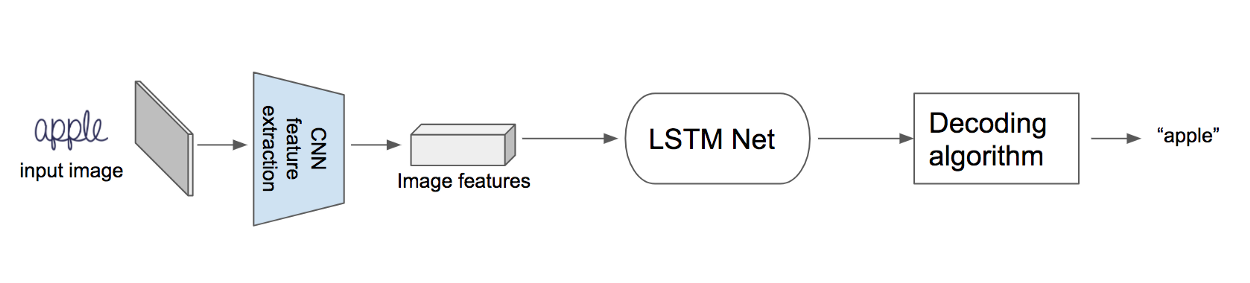
首先,將圖像輸入 CNN 中提取圖像特徵,接下來對這些特徵應用卷積神經網路,然後採用特殊的解碼算法進行解碼,解碼算法會利用每個時步,產生的長短期記憶網路輸出,並產生最終的標籤。
詳細的架構將會在下面給出,兩個縮寫的含義分別為:
FC — 全連接層
SM – softmax層
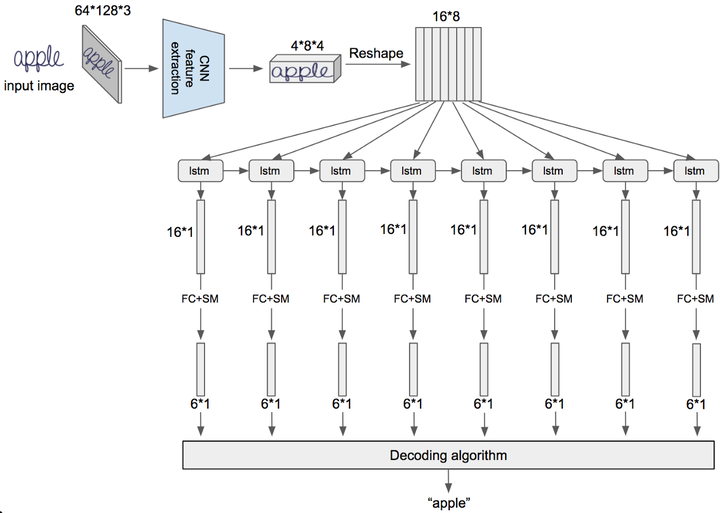
圖片的形狀為:高 64,寬 128,3 個通道。
正如之前所見,我們將這幅圖像輸入 CNN 特徵提取器中,會輸出一個形狀為 4*8*4 的張量,我們將圖片「apple」與這個結果放在一起你就能理解如何解讀這個張量。4 就是高度,8 為寬度(這些都是空間維度),通道數為 4,也就是說我們將 3 通道的輸入圖片轉換為了 4 通道的張量。
從實用的角度出發,通道數應該更多,但我們構建小型的示例網路,因為這樣更適合用幻燈片進行講解。
接下來我們進行形狀重塑,在這之後我們得到了由 8 個向量組成的序列,每個向量中含有 16 個元素,然後我們將這 8 個向量輸入 LSTM 網路中,並得到相應的輸出 — 同樣是 16 個元素組成的向量,現在,我們將全連接層應用到這些輸出上,緊接著應用 softmax 層並獲得 6 元素的向量,這個向量包含了每一步 LSTM 中,所觀察到的字符的概率分布。
實際上,CNN 輸出的向量數量可以達到 32,64 甚至更多,這取決於具體的任務。並且在部署時,最好能夠使用多層雙向 LSTM,不過在這裡,我們的例子中只解釋最重要的概念。
解碼算法又是如何起作用的呢?
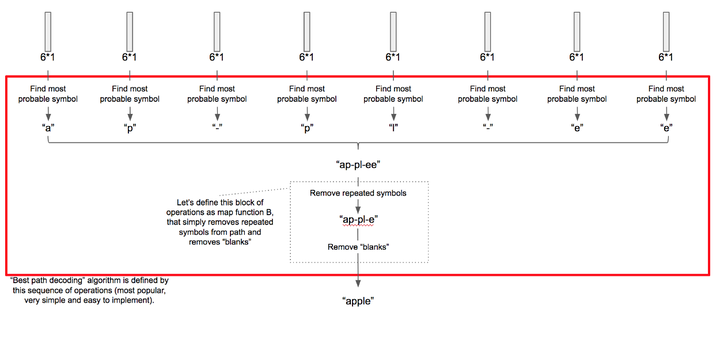
在上面的圖表中,對於每一個 LSTM 時步,我們都有 8 個概率分布向量,將每個時步中最大概率對應的符號抽取出來,我們得到了由8個字符組成的字符串,然後我們必須把所有連續重復的字符合併為一個,在我們的例子中,兩個連續的字母「e」被合併成了一個。
特殊的空白符,使我們能夠將初始標籤中重復的字符分離開來,所以我們在字符表中,加入空白字符來訓練神經網路,使其能夠預測重復字符之間的空白符,最後我們再刪除這些空白符。這個處理過程請看下面的圖示:
在訓練我們的網路時,我們用 CTC Loss 層替換瞭解碼算法,這在我們的第二段影片中有相應的解釋,不過目前影片中用的是俄語,但我們會盡快推出英文版,對此深感抱歉。
我們的實現中使用了稍微複雜的 NN 架構,如下面所示,但核心的原理是相同的。
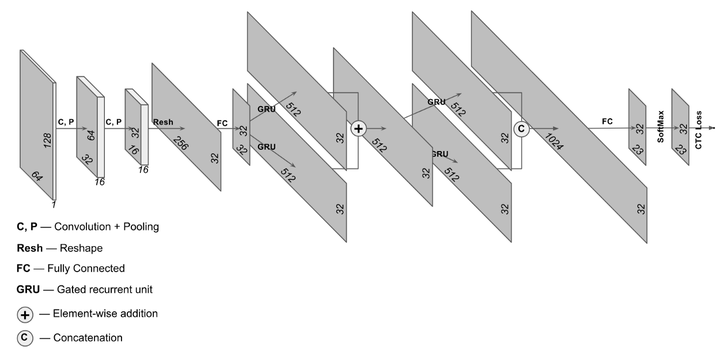
在模型訓練完成後,我們將其應用到驗證集上並取得了非常精確的辨識效果。同時我們也對每一步 CNN 操作輸出的概率矩陣,進行了可視化操作,如下所示。

矩陣的行對應所有的字符,包括空白字符,列對應著 RNN 的步驟。
總結
我們非常高興與大家分享我們的經驗,相信這些影片段課程、教程、隨時可用的人工數據以及源代碼,能幫助你獲得直觀的認識,人人都能從零開始,搭建一個車牌辨識系統。
 |
0 comments:
張貼留言