來源:鳳凰科技

如何讓公共健康管理更簡單
Intetix Foundation(英明泰思基金會)由從事數據科學、非營利組織和公共政策研究的中國學者發起成立,致力於通過數據科學,改善人類社會和自然環境。通過聯絡、動員中美最頂尖的數據科學家和社會科學家,以及分布在全球的志願者,我們創造性地踐行著我們的使命:為美好生活洞見數據價值。
原文:
How Semantic Data Analytics Benefits Population Health
Management http://healthitanalytics.com/news/how-semantic-data-analytics-benefits-population-health-management
雖然關係數據庫的研究,應用於基本的病人護理,但是語義學數據的分析,是可靠的公共健康管理系統不可或缺的。

在複雜的病人護理領域,存在的問題總是比答案多。臨床醫生和學者正在通過常規檢查、複診和治療發現新的疾病,並且他們對人類的身體健康的認知也是指數級的拓展。
對大多數內科醫生而言,他們需要學習最新臨床指導方針細節、最新的藥物治療方式,並瞭解精準醫藥最先進的發展。但是在照顧病人、滿足常規要求和科技更新的沈重壓力下,他們又不可能一直保持閱讀大量的文章和研究。
這時大數據分析就大有用武之地。分析工具可以通過同步電子健康記錄、保險需求、病人自己記錄的健康數據、甚至基因檢測結果等,為可行的臨床決定提供支撐,從而增進內科醫生對病人護理的瞭解,填補醫學院畢業後,多年內知識更新的鴻溝。
然而哪怕是最新最好的傳統分析方法,也難以滿足現代醫療健康飛速發展的需求,即使小規模的HER數據挖掘,也是非常困難和昂貴的,這其中面臨很多數據完整性的障礙,這些障礙將降低結果的可信度。獲得乾淨、完整和標準化的數據源已經足夠困難。
但是更加困難的是,如何將分析結果轉換成對患者更好的治療。即使一個機構成功克服了一些基本障礙,開始進行公共健康管理,它也會受限於它所使用的原始科技。
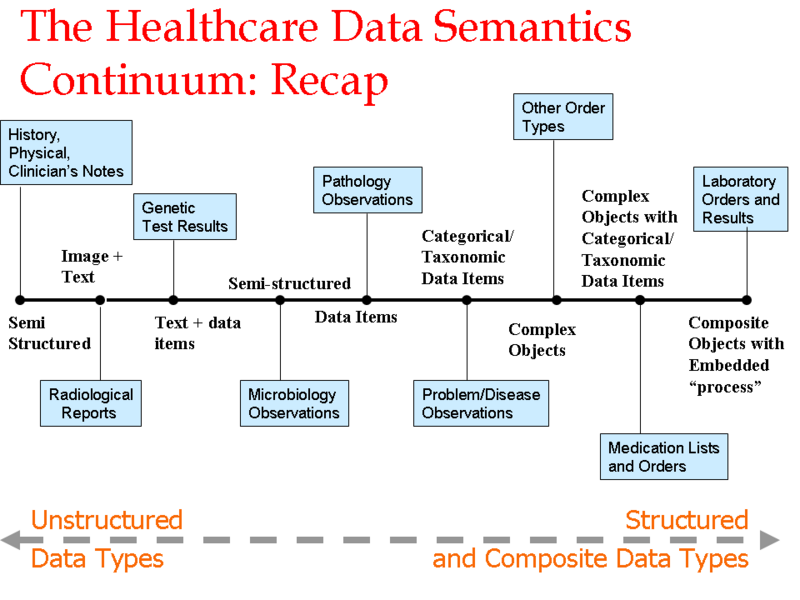
在最新的先進大數據分析技術系列中,我們探索了當前分析工具的極限和語義數據庫,改變醫療健康機構從事公共健康管理方式的可能性。
語義分析深植於與最當前版本的大數據分析相同的概念:關係數據庫。

通過這個數據庫,用戶可以回答「Mary Fletcher 加入的是哪一個保險?」,「James Wong 居住在哪裡?」,「有多少位患者居住在主大街?」等問題。

關係數據庫的困境
即使在表格上增加更多的竪列試圖,提高解答病人疑問的可能性, 簡單的關係數據庫,仍會變得難以控制,以致於不能提供複雜問題的答案。
Linda
Sanchez 以新病人的身份來到診所。 她在掛號時提供了她的地址和保險公司資訊。她沒有糖尿病,但是她的BMI指數已經到了高危範圍,而且她在服用抗抑鬱類藥物。
為了能夠積極地管理Linda Sanchez,她的診所需要知道什麼?第一, 她換上心腦血管的臨床風險。第二,可以阻止發生這類疾病的措施。 Linda的健康管理人員需要知道監視這些指標,而且她也得明白為什麼Linda不能很好的控制她的體重,並且幫助她調節飲食和督促她鍛鍊。

她的健康管理人員可能會問如下的問題:
· Linda可以在商店裡買到新鮮食材或者其他健康飲食的材料嗎?
· Linda有一個可以方便安全的地方鍛鍊嗎?她有經濟能力去參加一個健身房嗎?或者健康管理人員要為她制定一個低成本健身方法?
·Linda可以便捷的在當地的藥房開出她抗抑鬱的藥物嗎?她按時開藥嗎?
一下子這個健康管理人員,可能要處理大量的資訊,這些數據可能大相徑庭。
她可能需要接觸人口調查數據,需要通過保險紀錄查看Linda的病史,瞭解Linda社區中藥店的開藥率,她也需要問關於Linda的各式各樣的問題, 而不是Mary,James或者John的,沒有任何一家健康組織會為每一位病人量身定做一個數據銀行。
沒有任何一個數據科學家可以預測,健康管理人員會提出怎樣的問題,或者他們需要怎樣的數據組合。 這種程度的公共健康管理,關係數據庫已經無法滿足了,太多數據有著不一樣的結構,僅僅用電子數據表已經不能解答複雜的問題。

語義數據庫的出場
語義數據庫不是簡單的陳列數據元素,而是將概念都鏈接在一起,數據可以在語義上的連接起來,就像人類大腦一樣。
當語義數據庫運用到管理Linda的健康狀況的時候,益處就更加明顯了。比如, 從最近的美國人口普查裡,提取的家庭收入數據中, 數據策展人員可以講在中心城市的東大道列為低收入社區。

Linda
Sanchez的地址在東大道上,所以她很有可能是低收入人群
Linda Sanchez [病人編號106]
[病人106地址]=[東大道]
[東大道]=[低收入]
[病人編號106]=[低收入]
結論:Linda Sanchez可能是低收入
假設Linda的健康管理人,取得了所有在東大道上的商店資訊,每個都整理歸類,快餐店,事務所,賣衣服的,賣菜的和藥房。 這樣她就可以回答更加複雜的公共健康管理的問題了,比如說:「有多少我的病人住在低收入社區,而且沒有買菜的店?」「在中心城市哪些藥房的處方藥開藥率最低?」

管理病人健康變得容易起來,因為健康管理人員不需要通過一系列調查梳理出Linda很難買到飲食中所需要的新鮮蔬菜,她也不用等到Mary Fletcher因為哮喘發作來急診才知道因為她在低收入地區的藥房,從而無法即使開藥。 取而代之的是,只要從這很小的語義數據庫中她就可以知道:
· 在這個區域里有X名病人有糖尿病
· 在這個區域里有X名病人使用Medicare為他們的保險,可能需要在老年的時候在家
看護
· 有X名有糖尿病的病人使用這兩個藥房,其中一個藥房並不能滿足他們的需求
· 這部分的病人住在低收入社區可能需要交通工具才能來診所
· 這部分病人無法獲得持續供給用藥因為他們的藥房不接受電子處方
· 我們可以在這群病人鄰近的食品商店設立免費流感疫苗注射點
· 這部分病人可能負擔不起多種藥物的處方因為他們是低收入人群
· 這個地區的人心臟病發病率很高,可以在這個地方建設公共小路,提供給他們鍛
鍊。
健康管理者可能不能通過關係數據庫,預見到這麼有深度的問題,也不能在這種原始數據形態下提問題,來滿足她想要知道關於每個病人的問題。
語義數據庫填補了關係數據庫這個缺點,通過每套添加到語義結構裡的數據,健康機構就可以更瞭解他們的病人以及他們所處的環境,從而給出最好的治療方案。

0 comments:
張貼留言