
 |
| 上敦 AXXON 台灣總代理 |
世界正日益由能夠觀察、解讀並與周遭環境互動的機器所驅動。電腦視覺曾是人工智慧的一個細分領域,如今正影響著從醫療保健,到自動駕駛系統等各個產業,重新定義我們對科技,在生活中所扮演角色的認知。
2025 年,電腦視覺將不再僅限於影像辨識,更將涵蓋理解情境、預測行為,以及賦能機器與人類無縫協作。這場革命的背後是突破性的演算法,它們將抽象的像素,轉化為確實可行的洞察。
本報導,重點介紹 2025 年必知的電腦視覺演算法,涵蓋其核心原理和實際應用。
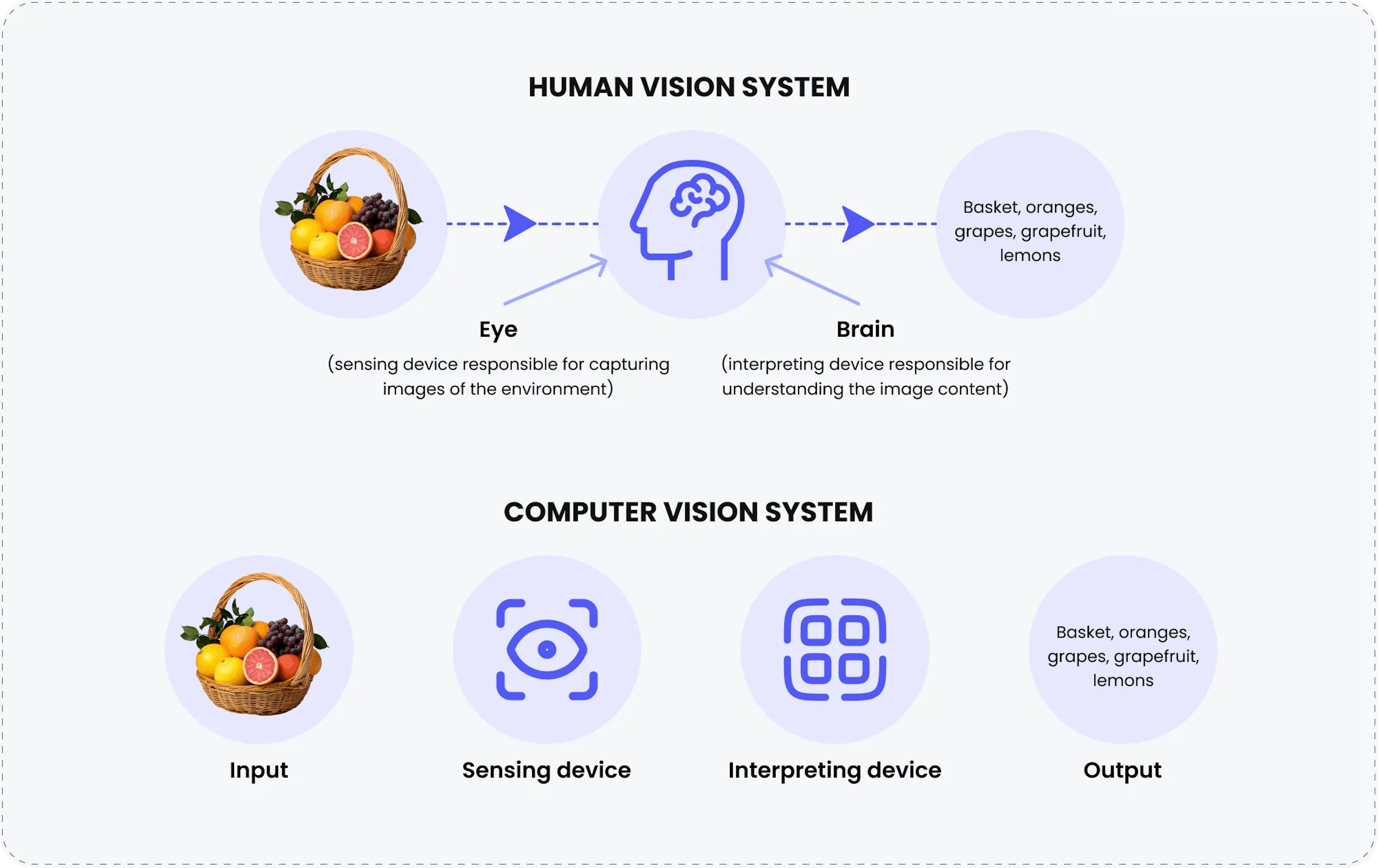
電腦視覺為何如此重要?
根據 Statista 統計,電腦視覺市場預計將顯著成長,預計到 2025 年其市場規模將達到 292.7 億美元。預計在 2025 年至 2030 年期間,該市場的複合年成長率 (CAGR) 將達到 9.92%,到 2030 年總價值將達到 469.6 億美元。
在全球,美國將引領這一成長,預計到 2025 年市場規模將達到 78 億美元,鞏固其作為電腦視覺產業最大貢獻者的地位。
電腦視覺使用先進的軟體和演算法,來複製人類的視覺和認知,使機器能夠執行物體辨識、缺陷檢測和品質控制等任務。
電腦視覺的核心組成部分包括:
影像擷取
此步驟涉及使用數位攝影機或感測器,所捕獲的影像或視覺數據,並將資訊儲存為二進位制數,這些原始資料是所有後續流程的基礎。
影像處理
影像處理透過預處理,提取基本幾何元素,並去除雜訊或不需要的元素。此步驟可確保獲得更清晰、更準確的影像,以便進一步分析。
分析
在此階段,高階演算法會對處理後的影像進行分析。深度學習和神經網路等技術,用於辨識物體、分類模式,並根據視覺數據做出決策。
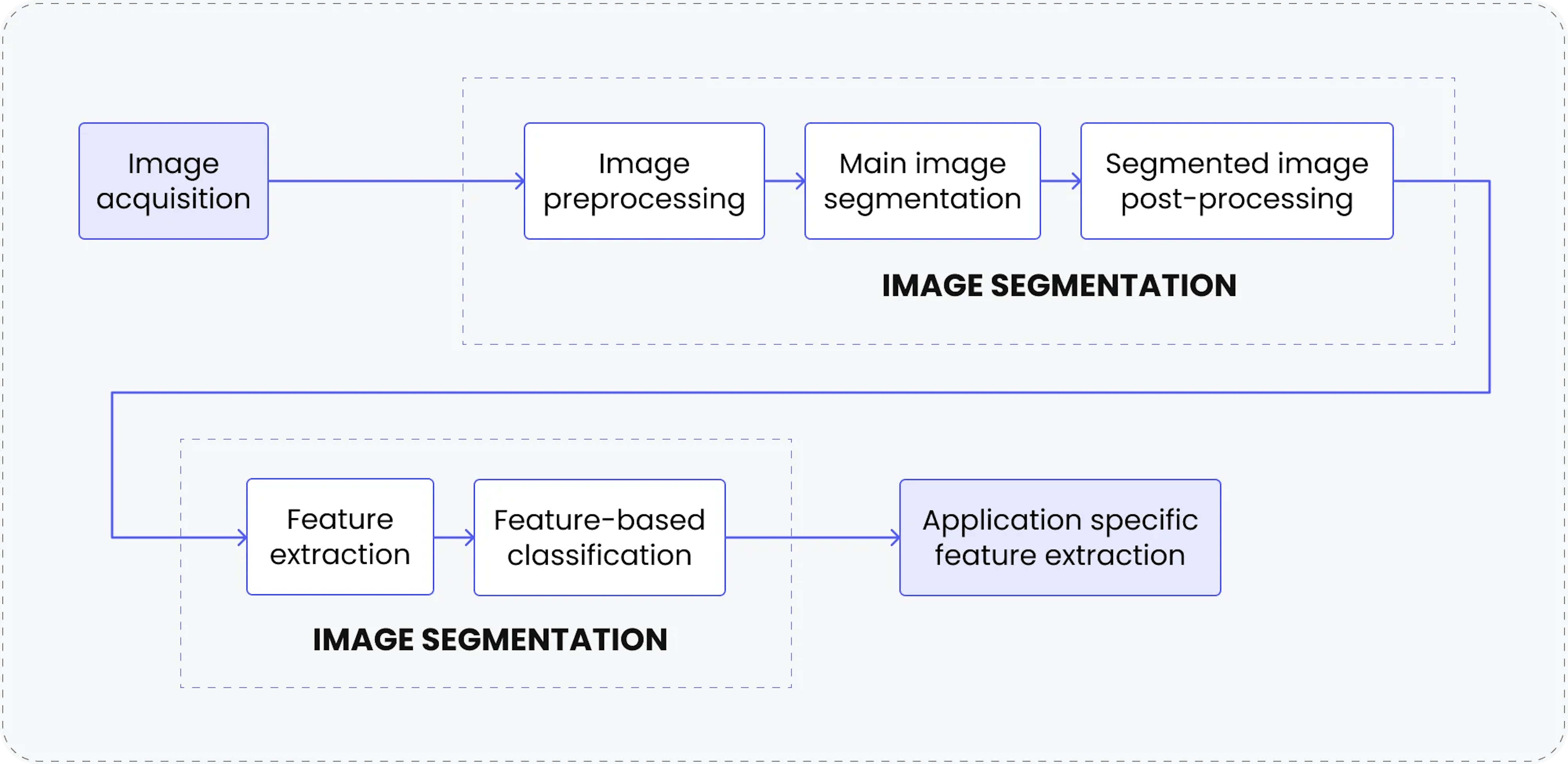
電腦視覺 (CV) 正在革新眾多產業,它使機器能夠解讀視覺數據並採取行動,促進創新並提高效率。從簡化日常流程到應對複雜挑戰,CV 推動著塑造未來的進步。以下是關鍵的應用案例,及其深遠影響:
自動駕駛汽車
電腦視覺,是汽車產業推動全自動駕駛交通發展的驅動力。這項技術透過使車輛具備分析周圍環境、偵測障礙物,和做出即時決策的能力,正在改變安全標準,並重新定義交通方式。最突出的例子是:高級駕駛輔助系統 (ADAS) 和全自動駕駛汽車。
醫療保健
電腦視覺與醫療保健的融合,正在重塑診斷和治療方法。演算法有助於辨識 X 光片、核磁共振成像 (MRI) 和 CT 掃描中的異常,從而實現早期疾病檢測和個人化治療方案。
零售與電子商務
無人收銀商店使用視覺系統即時追蹤商品,從而實現無縫結帳流程。在電子商務領域,服裝和化妝品的虛擬試穿工具,讓顧客在購買前就能看到產品,從而提升滿意度並減少退換貨。這些進步提升了使用者體驗,並提高了零售商的營運效率和獲利能力。
製造業
這些系統會仔細檢查產品是否有缺陷,確保裝配線上的產品完美無瑕。透過自動化品質控制和預測性維護,電腦視覺技術可以減少停機時間、最大限度地減少浪費,並提高整體生產效率,從而推動更具創新性和永續性的製造流程。
農業
搭載視覺系統的無人機,可以監測作物健康狀況、辨識病蟲害,並評估土壤狀況。自主機器人可以執行除草和收割等任務,優化資源利用並提高產量。透過提供即時洞察和自動化技術,電腦視覺技術支援永續農業,並幫助農民滿足全球糧食需求。
安全與監控
人工智慧驅動的視覺系統可以辨識可疑活動、增強人臉辨識功能,並提供即時警報,從而提升公共場所的安全。
娛樂與媒體
電腦視覺正在徹底改變娛樂產業內容的創作和消費方式。這項技術將創造力和精準度提升到了新的高度,從檢測和防止深度偽造到自動化影像編輯和增強特效。視覺演算法也應用於擴增實境 (AR) 和虛擬實境 (VR) 等沉浸式體驗,突破了敘事和使用者參與度的界限。
 Klacci 凱樂奇商用級智慧門鎖各種應用解決方案
Klacci 凱樂奇商用級智慧門鎖各種應用解決方案
11 種電腦視覺演算法:從經典到前瞻
多年來,電腦視覺技術取得了長足的發展,從基礎演算法發展到現代人工智慧驅動的方法,重新定義了影像處理和分析的可能性。以下概述探討了這些演算法的優勢、局限性和獨特應用案例,並重點介紹了它們在塑造電腦視覺未來方面的作用:
1. SIFT(尺度不變特徵變換,Scale-Invariant Feature Transform)
SIFT 是一種用於檢測和描述數位影像中,局部特徵的演算法。它辨識關鍵點並為其分配描述符 —— 用於物體檢測和辨識的量化細節。想像一下,在擁擠的體育場中試圖找到朋友 —— SIFT 對圖像執行類似的操作。它可以辨識角落或邊緣等獨特特徵,就像物體的「指紋」一樣。
優點:
- 對尺寸和方向變化具有穩健性。
- 在各種光照條件下均表現良好。
- 適用於醫學影像等精準應用。
- 用於影像拼接、物件辨識和 3D 重建。
缺點:
- 不適用於即時或大規模任務。
- 需要大量儲存空間來儲存關鍵點和描述符。
- 難以處理雜訊很大的影像。
應用案例:
- 影像拼接 - 透過匹配重疊影像建立全景圖。
- 物體辨識 - 即使影像經過變換也能辨識影像中的物體。
- 3D 重建 - 從多個視角建構模型。
- 醫學影像 - 對齊診斷掃描。
- 地圖繪製 - 用於自主導航的特徵檢測。
2. SURF(加速加強性特徵,Speeded-up Robust Features)
SURF 是一種用於檢測和描述,數位影像中局部特徵的演算法,目的在作為 SIFT 的更快替代方案。它可以定位關鍵點,並為其分配描述符,以進行物體檢測和辨識。SURF 可以理解為在人群中,快速辨識朋友的加速版 —— 它在保持準確性的同時注重效率,透過辨識邊緣和斑點等特徵,來創建物體的「指紋」。
優點:
- 由於運算簡化,速度比 SIFT 更快。
- 對縮放、旋轉和輕微的光照變化具有穩健性。
- 適用於即時應用。
缺點:
- 在極端光照或視角變化下,穩健性不如 SIFT。
- 由於注重速度,可能會失去精細細節。
- 對於非常大的資料集,仍然需要大量計算。
應用案例:
- 即時物體辨識 - 在影像處理等應用中,快速偵測特徵。
- 影像比對 - 在即時任務中辨識影像之間的相似性。
- 擴增實境 - 追蹤物體以疊加 AR 內容。
- 導航 - 機器人和自動駕駛汽車中的特徵檢測。
3. ORB(定向快速和旋轉簡報,Oriented FAST and Rotated BRIEF)
ORB 是一種快速且有效率的演算法,用於檢測和描述數位影像中的局部特徵,是作為 SIFT 和 SURF 的開源替代方案而開發的。它結合了 FAST 關鍵點偵測器和 BRIEF 描述符,並添加了旋轉和尺度不變性。對於注重速度和效率的應用,尤其是在即時或資源受限的環境中,ORB 是首選。雖然它可能無法提供與 SIFT 或 SURF 相同的精度,但其速度和多功能性,使其成為現代電腦視覺任務的熱門選擇。它廣泛應用於 AR/VR 應用、機器人技術(例如 SLAM,Simultaneous localization and mapping),以及其他資源受限的場景。
優勢:
- 極度快速高效,適用於即時應用。
- 開源,無許可限制。
- 旋轉和尺度不變,可實現可靠的特徵比對。
- 適用於大型資料集和低功耗設備。
缺點:
- 在複雜或吵雜的環境中,準確度低於 SIFT 或 SURF。
- 在光照劇烈變化的情況下,可能難以處理。
- 描述符有時會導致高維資料不符。
應用案例:
- 快速有效率地完成人臉辨識等任務。
- 行動應用 - 非常適合低功耗裝置上的 AR 應用或遊戲。
- 機器人 - 用於導航和 SLAM(同步定位與地圖建構)的特徵追蹤。
- 影像拼接 - 為即時系統提供更快的全景圖建立。
- 影像處理 - 在動態場景中進行逐幀特徵檢測。
4. Viola-Jones
Viola-Jones 框架是一種開創性的即時物體偵測演算法,最著名的應用是人臉偵測。該框架由 Paul Viola 和 Michael Jones 於 2001 年開發,使用級聯分類器快速有效地檢測數位影像中的物體。想像一下,Viola-Jones 就像一位目光敏銳的保全,正在掃描人群 —— 它會快速聚焦於可能包含目標物體的區域,跳過無關細節。
優點:
- 對於即時應用而言,速度極快且有效率。
- 能夠準確偵測簡單、輪廓清晰的物體,例如人臉。
- 能夠很好地適應不同的影像尺寸和解析度。
缺點:
- 僅限於特定的物體類型;對於複雜或雜亂的影像效果較差。
- 對光照、姿勢和方向的變化較為敏感。
- 如果偵測視窗與非物體區域重疊,則容易出現誤報。
- 在準確性和適應性方面,其表現不如現代深度學習方法。
應用案例:
- 人臉偵測 - 廣泛應用於相機應用、監控和生物辨識系統。
- 物體偵測 - 辨識預先定義的物體,例如眼睛、嘴巴或行人。
- 影像濾波 - 在預處理流程中快速進行物件濾波。
- 影像監控 - 即時偵測即時影像中的人臉或其他物體。
- 擴增實境 - 快速定位人臉或特徵以疊加擴增實境元素。
雖然它們並非 2025 年的「熱門」演算法,但在某些情況下仍然非常重要,並充當傳統電腦視覺與現代人工智慧,驅動方法之間的橋樑。
它們在哪些領域依然閃耀?
- 低資源環境 - ORB 和 Viola-Jones 演算法,非常適合運算能力有限的邊緣設備。
- 利基應用程式 — 影像拼接、3D 重建或小型專案等任務,可能仍然傾向於使用傳統方法,因為它們簡單易懂且易於解釋。
- 教育價值 - 這些演算法是學習電腦視覺基礎,和理解特徵提取原理的重要工具。
在深入研究尖端技術之前,理解基礎知識非常重要。現在,讓我們探索更先進的現代方法。
5. Mask R-CNN
Mask R-CNN 是一種先進的深度學習模型,專為實例分割而設計,它擴展了 Faster R-CNN,添加了一個分支,用於預測每個檢測到的物體的分割掩膜。該模型由何開明於 2017 年提出,能夠辨識和定位物體,並產生精確的像素級遮罩。一個貼切的例子就像一位技藝精湛的藝術家 —— 它不僅能辨識物體,還能精準地勾勒出它們的形狀。
優點:
- 結合物件偵測和分割,進行精確的實例層級分析。
- 適用於分割、物件偵測和關鍵點偵測等多種任務。
- 適用於各種資料集和物件類別。
缺點:
- 需要大量資源進行訓練和推理。
- 與簡單的模型相比,對每個實例進行分割會增加運行時間。
- 比基本的檢測模型更難實現和微調。
應用案例:
- 自動駕駛 - 分割和偵測行人、車輛和交通標誌等物體。
- 醫學影像 - 在 X 光或核磁共振成像 (MRI) 中,辨識感興趣的區域,例如腫瘤或器官。
- 影像分析 - 在影像來源中逐幀追蹤和分割物件。
- 零售分析 - 透過分割和計數單一產品來分析貨架庫存。
- 擴增實境 - 將 AR 元素疊加在分割的物件上,以實現無縫的使用者體驗。
6. YOLO(You Only Look Once)系列
YOLO 系列是一系列即時物體偵測模型,目的在提高速度和準確性。 YOLO 由 Joseph Redmon 於 2016 年首次提出,它將物體檢測重新定義為單一的回歸問題,一次性直接從影像中預測邊界框和類別機率。YOLO 就像是閃電般的快速掃描器 —— 它只需查看一次圖像即可立即辨識和定位物體。
它是單階段檢測器最重要的代表,以其在速度和性能之間的高效平衡而聞名。
優勢:
- 能夠以高幀率處理圖像和影像。
- 將物體偵測視為單一統一的任務。
- 可有效應用於從自動駕駛到監控等多個領域。
缺點:
- 難以偵測非常小或重疊的物體。
- 更快的版本優先考慮速度,可能會犧牲一些準確性。
- 需要標註良好的資料集才能獲得最佳效能。
應用案例:
- 監控 - 偵測即時安全資訊流中的物體或人員。
- 自動駕駛汽車 - 即時辨識行人、車輛和道路標誌。
- 零售分析 - 統計顧客數量、監控庫存或偵測貨架庫存。
- 醫療保健 - 檢測醫學影像(例如 X 光或超音波)中的異常情況。
- 運動體育分析 - 在快節奏的比賽中追蹤球員和裝備。
7. 視覺 Transformers (ViT)
視覺 Transformers (ViT) 是先進的模型,它採用了最初為自然語言處理設計的 Transformer 架構來處理影像。他們將圖像劃分為多個區塊,將每個區塊視為一個標記,並利用自注意力機制來理解影像中的全局關係。ViT 可以被視為一位戰略家,分析整個「大局」,而不是僅僅關注局部細節。
優點:
- 捕捉整個影像中的關係,在大型資料集上的表現優於傳統方法。
- 在影像分類、目標偵測和分割等任務中表現出色。
- DeiT 等現代改進方法在較小資料集上的效能有所提升。
缺點:
- 需要大量的標籤資料集才能達到最佳效能。
- 它需要大量的硬體資源,並且在資源匱乏的環境中使用受限。
- 與傳統方法相比,ViT 的訓練和調優更具挑戰性。
應用案例:
- 影像分類 - 醫療診斷等領域的高精度分類。
- 目標偵測 - 自動駕駛汽車和機器人中的高階偵測任務。
- 分割 - 用於 AR/VR 和影像編輯的精確影像分割。
- 醫學影像 — 以無與倫比的細節分析 X 光、MRI 和 CT 掃描。
- 衛星影像 - 擷取有意義的模式進行地理空間分析。
8. 神經輻射場 (NeRF,Neural Radiance Fields)
NeRF 是一項突破性的技術,用於從 2D 影像合成 3D 場景。NeRF 由 Ben Mildenhall 等人於 2020 年提出,它將場景表示為連續的體積場,預測任意 3D 點的顏色和密度。我們可以將 NeRF 想像成虛擬的雕塑家 —— 它們拍攝散落的 2D 照片,然後將其「雕刻」成逼真的 3D 模型。
優點:
- 能夠生成高品質、精細的 3D 重建,並具有逼真的光照和紋理。
- 適用於稀疏或非結構化的 2D 影像資料。
- 能夠在緊湊的神經網路中編碼複雜的 3D 場景。
缺點:
- 需要大量的訓練時間和硬體資源。
- 主要適用於靜態物體和環境,儘管動態的 NeRF 變體正在湧現。
- 依賴高品質、多樣化的輸入影像,才能獲得最佳效果。
應用案例:
- 虛擬實境 (VR) 和擴增實境 (AR) — 基於真實場景創建沉浸式環境。
- 3D 重建 — 將文化遺產、雕塑或環境數位化,用於保育和研究。
- 特效 — 在影像和遊戲中產生逼真的背景或物件。
- 地圖繪製與模擬 — 為機器人、自主導航或地理空間分析建立精確的 3D 地圖。
- 電子商務 — 顯示 3D 產品模型,打造更具互動性的購物體驗。
9. 對比學習 (SimCLR, BYOL;Contrastive Learning)
對比學習是一種自監督學習方法,它訓練模型區分相似和不相似的資料點。諸如 SimCLR(簡單對比表示學習)和 BYOL(自舉潛在學習)之類的方法利用這種技術,透過比較同一影像的增強視圖,從未標記資料中學習有意義的表示。想像一下,這就像訓練你的大腦從不同的角度或光照條件下辨識朋友一樣。
優點:
- 無需大量標記資料集,減少對人工標註的依賴。
- 產生適用於各種下游任務(例如分類或分割)的通用特徵。
- 學習到的特徵即使經過裁切、旋轉或顏色變化等變換,也能保持不變。
缺點:
- 需要較大的批量和強大的硬體,才能進行有效的對比比較。
- 學習到的表示的品質,很大程度上取決於合適的增強。
- 一些方法(尤其是 SimCLR)依賴大量負樣本,這可能會使實現變得複雜。
應用案例:
- 影像分類 - 預訓練模型,以提升下游分類任務的表現。
- 醫學影像 - 利用未標記的掃描資料,來建立穩健的特徵表示,用於疾病檢測。
- 物體偵測 - 透過從原始影像資料中學習不變特徵,來增強偵測模型。
- 推薦系統 - 從沒有明確標籤的使用者互動,或項目屬性中提取模式。
- 影像分析 - 從未標記的影像片段中,學習用於動作辨識或場景理解的表徵。
10. CLIP(對比語言-影像預訓練,Contrastive Language - Image Pretraining)
CLIP 是由 OpenAI 開發的突破性模型,它透過對比學習來學習連結文字和圖像。該模型基於龐大的圖像 - 字幕對資料集進行訓練,能夠理解視覺概念,並將其與自然語言聯繫起來。CLIP 類似於視覺和語言的雙語翻譯器 —— 它將你所看到的內容與你對其的描述無縫銜接。
優點:
- 彌合視覺數據和文字數據之間的差距,支持零樣本分類等任務。
- 無需額外微調即可推廣到未知任務和領域。
- 利用大規模資料集,在各種場景下實現穩健的效能。
缺點:
- 表現受訓練資料中存在的偏差影響。
- 訓練和佈署 CLIP 需要大量的運算資源。
- 在需要對同一類別進行細粒度區分的任務中存在困難。
應用案例:
- 零樣本分類 - 無需特定任務訓練即可將影像分類(例如,為博物館藝術品添加標籤)。
- 內容審核 - 根據文字描述辨識圖像中的不當或有害內容。
- 搜尋和檢索 - 在多媒體資料庫中啟用基於圖像或文字的搜尋。
- 創意應用程式 - 根據文字提示生成藝術作品或策劃視覺效果。
- 擴增實境 (AR) - 將現實世界中的物體與描述性標籤關聯,以增強使用者互動。
11. 擴散模型(Diffusion models)
擴散模型是一類生成模型,它透過逆轉雜訊添加過程來創建資料。經過訓練,這些模型可以模擬逐步添加和消除雜訊的過程,從而產生高品質的數據,例如圖像、音頻,甚至 3D 結構。擴散模型可以被視為數位雕塑家 —— 它們從一塊噪音開始,逐漸「雕刻」出有意義的圖案。
優點:
- 產生逼真的圖像和精細的資料樣本。
- 避免了生成對抗網路 (GAN) 的常見缺陷,例如模式崩潰。
- 適用於影像、音訊和分子生成等多個領域。
缺點:
- 由於需要多個迭代步驟,因此需要大量資源進行訓練和採樣。
- 產生輸出涉及多個步驟,與其他方法相比速度較慢。
- 對於初學者來說,實施和微調可能具有挑戰性。
應用案例:
- 影像生成 - 根據雜訊或文字描述創建逼真的影像(DALL·E 2,穩定擴散)。
- 文字轉圖像的轉換 - 根據創意產業的文字提示產生圖像。
- 音訊合成 - 產生高品質的音訊樣本,例如語音或音樂。
- 3D 模型生成 - 為遊戲、AR/VR 或設計設計 3D 物件或場景。
- 科學應用 - 分子建模、物理過程模擬或研究資料生成。

推動這些電腦視覺演算法流行的關鍵趨勢:
- 這些演算法在提供最先進的結果的同時,也能擴展到各個產業。
- 其中許多方法針對速度和效率進行了最佳化,這對於自動駕駛和擴增實境等動態任務至關重要。
- 降低數據依賴性。SimCLR 和 CLIP 等演算法,正在最大限度地減少對大型標記資料集的需求,使人工智慧更容易被應用。
- 它們的多功能性使其在醫療保健、製造、安全、娛樂等領域中廣泛應用。
- 邊緣人工智慧和輕量級模型的興起,滿足了邊緣和移動環境中,對運算效率的需求。
提供的演算法之所以流行,是因為它們符合 2025 年的關鍵需求:適應性、效率以及處理日益複雜任務的能力。
總結
電腦視覺不再只是關乎能夠「看」的機器,而是能夠以變革性的方式理解、分析並與世界互動的系統。在 2025 年,這些演算法不僅將推動創新,還將塑造企業的營運和擴展方式。
儘管計算需求和數據依賴性等挑戰依然存在,但效率、適應性和可擴展性的提升正在為更智慧、更互聯的未來鋪平道路。
從智慧自動化到 AR/VR 創新,Mad Devs 提供電腦視覺開發服務和機器學習解決方案,協助你的企業保持領先地位。讓我們為您解決難題,讓您專注於發展。

0 comments:
張貼留言