Google's DeepMind AI
Just Taught Itself To Walk
 |
|
0935-970-603 施正偉
|
leiphone 作者:杨晓凡

AI 科技評論按:在深度神經網路大行其道的現在,雖然大家總說,要改善深度學習的可解釋性、任務專一性等問題,但是大多數研究論文在這些方面的努力,仍然只像是隔靴搔癢。
而且,越是新的、具有良好表現的模型,我們在為模型表現感到開心的同時,對模型數學原理、對學習到的表徵的理解,也越來越進入到了放棄治療的心態;畢竟,深度學習具有超出經典 AI 的學習能力,正是因為能夠學習到新的、人類目前還無法理解的表徵。
而且,越是新的、具有良好表現的模型,我們在為模型表現感到開心的同時,對模型數學原理、對學習到的表徵的理解,也越來越進入到了放棄治療的心態;畢竟,深度學習具有超出經典 AI 的學習能力,正是因為能夠學習到新的、人類目前還無法理解的表徵。
近期 DeepMind 的一篇論文《An Explicitly Relational Neural Network Architecture》(一種顯式的關係性神經網路架構,arxiv.org/abs/1905.10307)似乎在這面高牆上,打開了一個口子。他們想辦法把深度學習和符號化的表徵連接起來,而且著重在意表徵的多任務通用和重覆使用能力,而且取得了有趣的初步成果。
小編把這篇論文的內容簡單介紹如下。
小編把這篇論文的內容簡單介紹如下。
重新思考我們需要什麼樣的表徵
當人類遇到沒有見過的新問題時,他們能回憶過往的經驗,從那些乍一看沒什麼關係,但在更抽象、更結構化的層次上,有不少相似度的事情中獲得靈感。
對於終生學習、持續學習來說,這種能力是非常重要的,而且也給人類帶來了很高的數據效率、遷移學習的能力、泛化到不同數據分布的能力等等,這些也都是當前的機器學習,無法比擬的。我們似乎可以認定,決定了所有這些能力的最根本因素,都是同一個,那就是決策系統學習,建構多種任務通用的、可重覆使用的表徵的能力。
對於終生學習、持續學習來說,這種能力是非常重要的,而且也給人類帶來了很高的數據效率、遷移學習的能力、泛化到不同數據分布的能力等等,這些也都是當前的機器學習,無法比擬的。我們似乎可以認定,決定了所有這些能力的最根本因素,都是同一個,那就是決策系統學習,建構多種任務通用的、可重覆使用的表徵的能力。
一個多種任務通用、可重覆使用的表徵,可以提高系統的數據效率,因為系統即便是遇到了新的任務,也知道如何建構與它相關的表徵,而不需要從零開始。
理論上來說,一個能高效利用多種任務通用、可重覆使用的表徵的系統,實際上也就和能學習,如何建立這樣的表徵的系統差不多。更進一步地,如果讓系統學習解決,需要使用到這樣的表徵的新任務,我們也可以期待這個系統,能夠學會更好地建立這樣的表徵。
所以,假設一個系統從零開始學習不同的任務,那麼除了它學習到的最初的表徵之外,之後的所有的學習,都像是遷移學習,學習的過程也將是一如既往地,不斷累積的、連續的、終生持續的。
理論上來說,一個能高效利用多種任務通用、可重覆使用的表徵的系統,實際上也就和能學習,如何建立這樣的表徵的系統差不多。更進一步地,如果讓系統學習解決,需要使用到這樣的表徵的新任務,我們也可以期待這個系統,能夠學會更好地建立這樣的表徵。
所以,假設一個系統從零開始學習不同的任務,那麼除了它學習到的最初的表徵之外,之後的所有的學習,都像是遷移學習,學習的過程也將是一如既往地,不斷累積的、連續的、終生持續的。
在這篇論文中,DeepMind 提出的建構一個這樣的系統的方法,其實源於經典的符號化 AI 的啓發。建構在一階謂詞計算的數學基礎上的,經典符號化 AI 系統,它們的典型工作方式,是把類似邏輯的推理規則,作用在類似語言的命題表徵上,這樣的表徵自身由對象和關係組成。
由於這樣的表徵有聲明式的特性和複合式的結構,這樣的表徵天然地具有泛化性、可以重覆使用。不過,與當代的深度學習系統不同,經典 AI 系統中的表徵,一般不是從數據學習的,而是由研究人員們手工建構的。
目前這個方向研究的熱點,是想辦法結合兩種不同做法的優點,建構一個端到端學習的可微分神經網路,然後神經網路中也可以帶有命題式的、關係性的先驗,就像卷積網路帶有空間和局部性先驗一樣。
由於這樣的表徵有聲明式的特性和複合式的結構,這樣的表徵天然地具有泛化性、可以重覆使用。不過,與當代的深度學習系統不同,經典 AI 系統中的表徵,一般不是從數據學習的,而是由研究人員們手工建構的。
目前這個方向研究的熱點,是想辦法結合兩種不同做法的優點,建構一個端到端學習的可微分神經網路,然後神經網路中也可以帶有命題式的、關係性的先驗,就像卷積網路帶有空間和局部性先驗一樣。
這篇論文中介紹的網路架構,基於非局部性網路架構的近期研究成果,這種網路架構可以學會發現,並運用關係資訊,典型的比如 Relation nets 以及基於多頭注意力的網路。
不過,這些網路生成的表徵,都沒有什麼顯式的結構,也就是說,找不到什麼從表徵中的一部分,到符號化媒介中的常用元素(命題、關係、對象)的映射。
如果反過來探究這些元素,在這樣的表徵中是如何分布的,可以說它們分散地遍布在整個嵌入向量中,從而難以解釋,也難以利用它的命題性,並在下游任務中運用。
不過,這些網路生成的表徵,都沒有什麼顯式的結構,也就是說,找不到什麼從表徵中的一部分,到符號化媒介中的常用元素(命題、關係、對象)的映射。
如果反過來探究這些元素,在這樣的表徵中是如何分布的,可以說它們分散地遍布在整個嵌入向量中,從而難以解釋,也難以利用它的命題性,並在下游任務中運用。
PrediNet 簡介
DeepMind 帶來了新網路架構 PrediNet,它學習到的表徵中的不同部分,可以直接對應命題、關係和對象。
把命題作為知識的基礎部件的想法,由來已久。一則元素聲明可以用來指出,一組對象之間存在某種關係;聲明之間可以用邏輯操作連接(和、或、否等等),也可以參與到推理過程中。PrediNet 的任務,就是學習把圖像之類的高維數據,轉換為命題形式的表徵,而且這個表徵可以用於下游任務。
PrediNet 模組可以看做,是由三個階段組成的流水線:注意力 attention、約束 binding 和評價 evaluation。注意力階段會選擇出成對的感興趣的對象,約束階段會借助選出的成對對象,把一組三元謂詞中的前兩個實例化,最後評價階段,會計算三元謂詞中的最後一個的(標量)值,判定得到的聲明是否為真。(更具體的介紹見論文原文)

PrediNet 網路架構
實驗測試
目前還沒法,直接把 PrediNet 用於大規模複雜數據;而且為了對提出的架構,有足夠扎實的科學理解,以及便於和其它方法進行細緻的比較,用小數據、小計算量做實驗,也是比較合適的。實驗測試的目標有兩個:1,驗證 PrediNet 是否能學習到希望的多任務通用、可重覆使用的表徵;2,如果前一個目標為真,研究它成立的原因。
作者們設計了一組「猜測關係」遊戲,是相對簡單的分類任務。它的玩法是,首先要學習表徵,一組繪製在 3x3 網格中的圖形,然後對於一張含有多個圖形的大圖,判斷給出的一條關於大圖中的,圖形間的關係的聲明是否為真。
雖然 PrediNet 本身學習到的命題,都只是很對兩兩成對的對象的,這個猜測關係遊戲需要的,是學習可能會牽扯到多個對象的複合關係。
實驗測試
目前還沒法,直接把 PrediNet 用於大規模複雜數據;而且為了對提出的架構,有足夠扎實的科學理解,以及便於和其它方法進行細緻的比較,用小數據、小計算量做實驗,也是比較合適的。實驗測試的目標有兩個:1,驗證 PrediNet 是否能學習到希望的多任務通用、可重覆使用的表徵;2,如果前一個目標為真,研究它成立的原因。
作者們設計了一組「猜測關係」遊戲,是相對簡單的分類任務。它的玩法是,首先要學習表徵,一組繪製在 3x3 網格中的圖形,然後對於一張含有多個圖形的大圖,判斷給出的一條關於大圖中的,圖形間的關係的聲明是否為真。
雖然 PrediNet 本身學習到的命題,都只是很對兩兩成對的對象的,這個猜測關係遊戲需要的,是學習可能會牽扯到多個對象的複合關係。
雖然 PrediNet 本身學習到的命題,都只是很對兩兩成對的對象的,這個猜測關係遊戲需要的,是學習可能會牽扯到多個對象的複合關係。

遊戲介紹:(a)訓練集中包含的樣本對象 (b)五種不同的可能行/列排列模式 (c)單個任務預測的示例 (d)多任務預測示例
多種形狀和關係的排列組合,使得這個任務的變化有相當多種,是比較理想的測試表徵,及邏輯能力的設定。
作者們對比的幾種模型,都帶有一個卷積輸入層、中央模組、以及一個用於輸出的多層感知機;中央模組是區別所在,PrediNet 或者其他的基準模型。
數據效率
用十萬組樣本訓練以後,5 種模型的對比如下。PrediNet 是唯一一個在所有任務上,都取得超過 90% 準確率的模型;在某些任務中,相比基準模型,甚至有 20% 的提升。

表徵學習能力
作者們設計了四個階段的模型學習,透過在不同階段測試模型,可以探究模型的表徵學習能力。從空白模型開始,首先學習一個任務(即無預訓練的單任務學習);其次學習多種不同任務(在第一個任務的基礎上,即有預訓練的多任務學習);接著凍結 CNN 層和中央模組,僅更新多層感知機;最後凍結 CNN 層,更新中央模型和多層感知機。這四個階段中不同模型的表現如下圖。
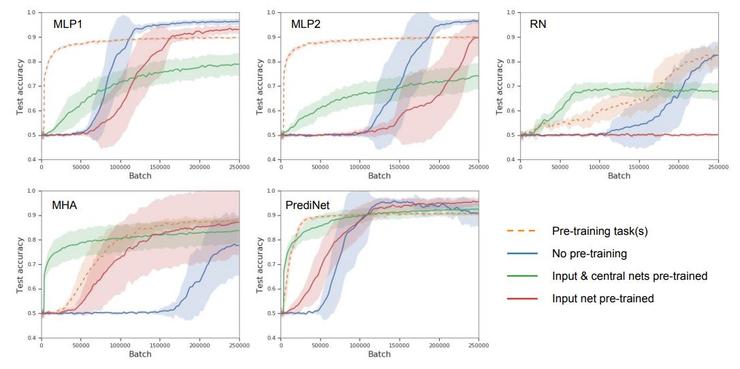
首先,橫坐標是訓練樣本數量,縱坐標是準確率,即模型表現隨訓練樣本增加的變化,那麼所有曲線都是越貼近左上角越好,這裡已經能看出 PrediNet 的優勢。
其次,作者們認為尤其值得注意的,是第三個階段的表現,凍結 CNN 層和中央模組,僅更新多層感知機,圖中綠線。凍結現有的表徵不變,向新的任務適應(遷移),PrediNet 的學習速度是最快的,也是唯一一個在訓練結束後,得到了 90% 準確率的模型。這就說明了 PrediNet 學習到的表徵,確實更加多任務通用。
其次,作者們認為尤其值得注意的,是第三個階段的表現,凍結 CNN 層和中央模組,僅更新多層感知機,圖中綠線。凍結現有的表徵不變,向新的任務適應(遷移),PrediNet 的學習速度是最快的,也是唯一一個在訓練結束後,得到了 90% 準確率的模型。這就說明了 PrediNet 學習到的表徵,確實更加多任務通用。
模型可視化
為了更好地理解 PrediNet 的計算行為,作者們製作了一些可視化,如圖。

訓練後的 PrediNet 的注意力頭的熱力圖。上方:在判斷是否形同的任務中訓練;下方:在判斷是否出現的任務中訓練

主成份分析(PCA)
結合多種實驗和分析,作者們認為 PrediNet 確實有一定的關係解耦能力,這也正是研究開始時,希望得到的能學習到良好的表徵的模型所需的。
結論
作者們展示了一個理論上,可以學習到抽象邏輯的模型,而且它還和端到端學習相容;網路可以自行從原始數據中,學習到對象和它們的關係,從而繞過了傳統 AI 中手工特徵帶來的種種問題。作者們的實驗顯示,網路可以學習到顯式命題的、關係性的表徵,從而在數據效率、泛化性、可遷移性方面,都有大幅改進。
不過這僅僅是非常初步的研究,完全開發這個思路的潛力,並把它應用在更複雜的數據、更複雜的實際任務中,還需要很多後續研究。
不過這僅僅是非常初步的研究,完全開發這個思路的潛力,並把它應用在更複雜的數據、更複雜的實際任務中,還需要很多後續研究。
另一方面,這篇論文的重點,在於獲得這樣的表徵,而非應用它。不過由於這種模型架構,帶有的良好先驗,PrediNet 模組生成的表徵,和謂詞計算是自然地相容的,這就為後續的各種符號邏輯運算,做了良好的鋪墊。
這個基礎上的改進,可以考慮增加循環連接,這可能會讓模型具有迭代和序列計算能力;也可以考慮把它用於強化學習,可以對目前的深度強化學習的各方面問題,都帶來改進。
這個基礎上的改進,可以考慮增加循環連接,這可能會讓模型具有迭代和序列計算能力;也可以考慮把它用於強化學習,可以對目前的深度強化學習的各方面問題,都帶來改進。

0 comments:
張貼留言