AI powered face recognition for smart cities and smart retail.
禾企 SHANY 紅外線 熱顯像儀 熱成像 熱顯測溫 100% 台灣製造
在第一篇與第二篇文章中,我們分別介紹了人臉辨識發展的主要脈絡,以及目前主流的人臉辨識算法,本文我們將對人臉辨識的一個重要應用方向進行介紹。
在人臉辨識中,有一類應用叫做人臉屬性辨識,它主要是透過分析人臉圖像,來辨識人物的各種屬性或者狀態,然後根據當前人物的狀態,做出一些針對性的處理,在零售行業中典型的應用場景就是精準行銷。隨著近幾年深度學習的快速發展,人臉屬性分析也獲得了越來越多的關注。
1 人臉屬性辨識簡介
關於人臉屬性的研究方向大致可分為兩類,一類是人臉屬性估計,即辨識一張圖片中人臉的某些屬性,比如性別、表情,歡樂程度等等;另外一類是人臉屬性編輯,簡單來說就是改變、生成或去除某些屬性,比如把一張臉變的更老,預測未來的相貌,或是在一張臉上添加一副白框太陽鏡等等。
早期關於人臉屬性辨識的研究,大多採用基於特徵臉的方法,它主要用到了主成分分析(PCA)。計算所有訓練樣本的特徵臉,也就是將人臉的形狀和紋理進行主成分分析,生成對應的特徵向量,即所謂的特徵臉。
這個特徵臉,也可以作為特徵用於人臉辨識。在人臉屬性分析當中,假定第 i 個樣本對應的特徵臉為 Φi,對應的人臉屬性值為 yi,這個屬性可以為年齡或者性別或者其它。
簡單來說人臉屬性辨識問題,可以透過估計下述映射矩陣 R 進行解決:
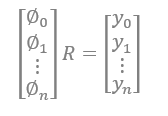
而人臉屬性編輯,則可以透過估計下述回歸矩陣 B 進行解決:
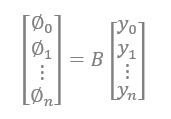
當然,實際處理的時候並沒有這麼簡單,因為先要對特徵臉對應的特徵向量進行分解,將表徵人身份的特徵剔除出去,只留下那些影響屬性變化的特徵。
正是由於早期基於特徵臉的方法,在對人臉屬性辨識,和屬性編輯這兩套算法上,是一個對偶問題,我們習慣性的在提起人臉屬性辨識的時候,默認不僅僅是屬性辨識,還包括了屬性編輯。
當進入深度學習階段以後,人臉屬性辨識和人臉屬性編輯,從算法角度上來說,就逐漸的區分開了。
說到這裡,插一個題外話,筆者曾經在與其他研究人員交流的過程中,被問到過一個問題,就是年齡辨識,為什麼要使用回歸的方式,而不是將每個歲數當作一個標籤採用分類的方法。這個問題非常突然,當時筆者給出的回答並不十分準確,但是現在可以準確的告訴大家答案:正是因為在傳統算法中,基於特徵臉的人臉屬性辨識,尤其是年齡估計是使用回歸估計的方法,所以在早期的基於深度學習的人臉屬性辨識中,經常會採用回歸的方法來辨識部分人臉屬性。
人臉屬性估計透過特徵提取,和訓練分類器來實現,而人臉屬性編輯透過訓練,生成模型來實現,其主要有兩個分支:生成對抗網路(generative adversarial networks, i.e., GANs)以及變分自動編碼器(variational autoencoders, i.e., VAEs)。有論文報導裡,給出了深度學習的人臉屬性估計和編輯的演變歷史,分別見圖 1 和圖 2。
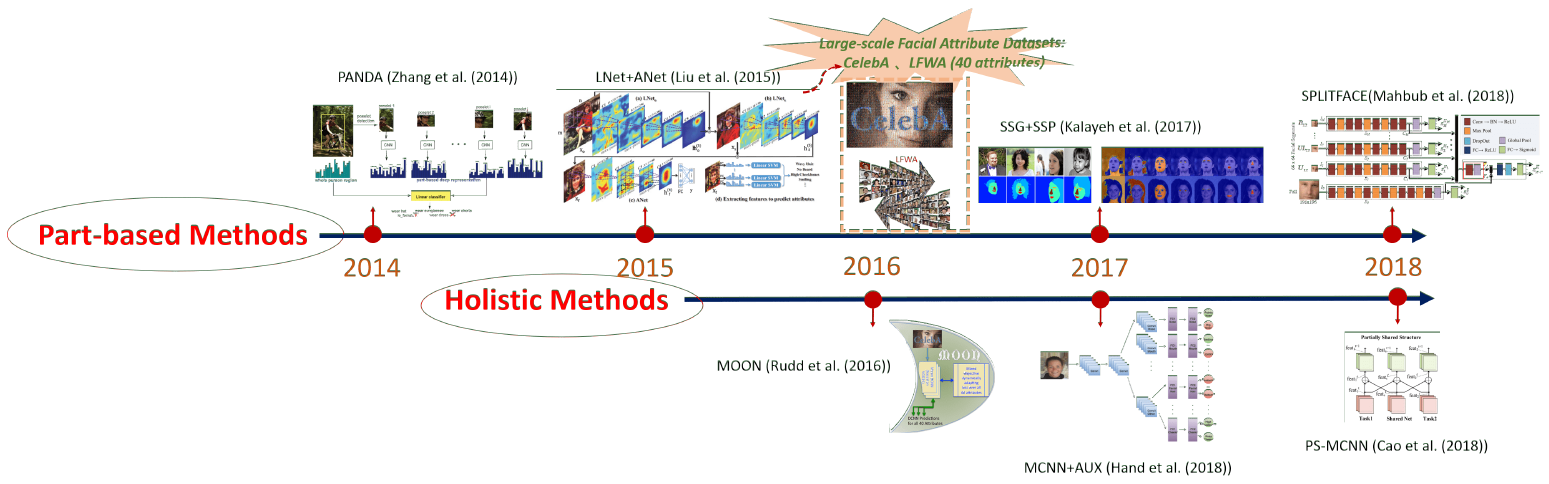
如圖 1 所示,深度學習人臉屬性估計的研究可以追述到 Zhang
et al. 的論文發表,人的全身圖片作為模型輸入,不僅有人臉屬性的估計,也有身體屬性的估計。接著 LNet 和 ANet 的興起推動人臉屬性估計成為獨立的研究方向,只有人臉圖片作為模型輸入。與此同時,兩個擁有 40 個標注屬性的大型數據庫,即 CelebA 和 LFWA 公開於世,進一步推動了人臉屬性估計方法的發展。
人臉屬性編輯方法的演變見圖 2,基本所有方法都是隨著 GANs 和 VAEs 的發展,一起發展而來。最早的編輯模型 DIAT,嘗試用簡單的生成對抗網路生成人臉屬性。緊接著,條件 GANs 和 VAEs 的發展,推動了基於屬性標籤模型的快速發展,這類模型有個重要的優勢,就是可以同時改變多個屬性,但其實這也是把雙刃劍,因為模型不能保證不相關屬性不被改變。事實上,直到現在,如何同時改變多個屬性,但是又保證不相關屬性不變,如何找到這個平衡仍然是個待解決的問題。
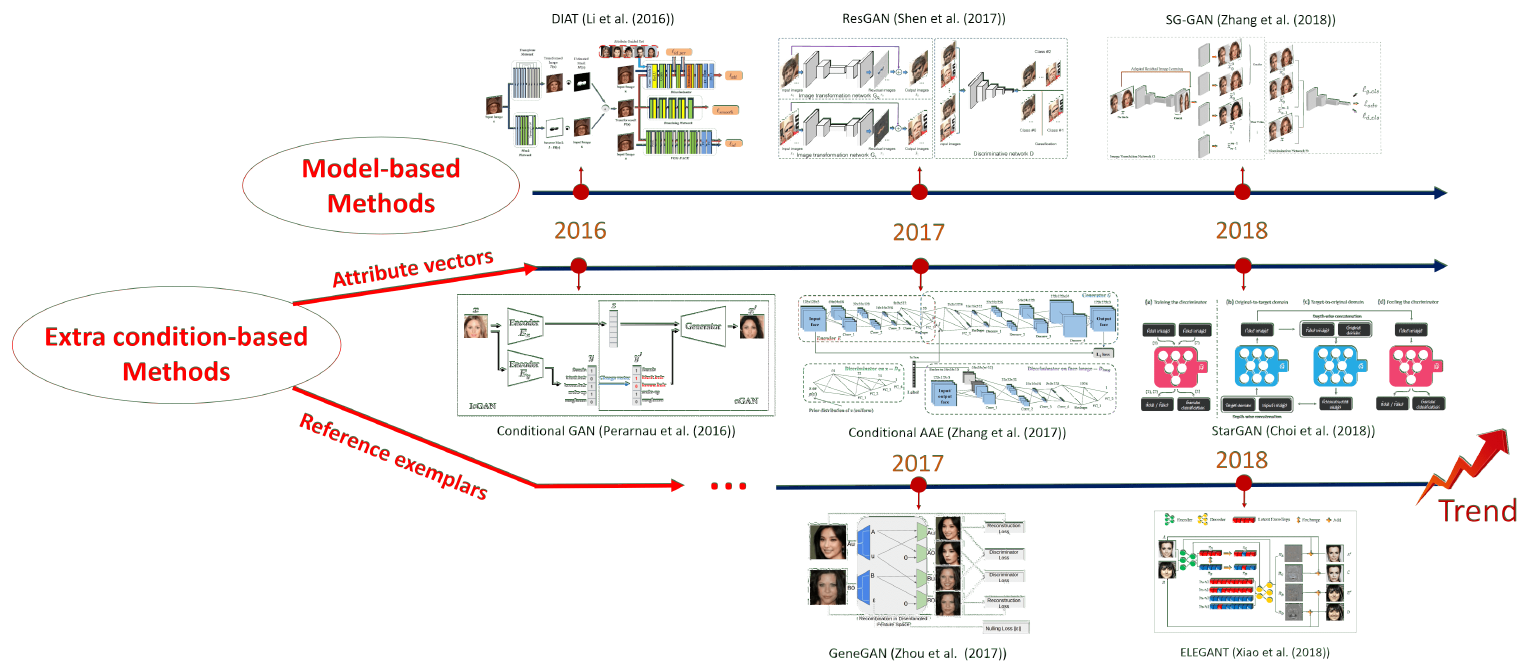
2 人臉屬性辨識的難點及解決方案
人臉屬性辨識最大的困難,就在於樣本的不充分和不均衡。
以年齡為例,大量存在的樣本是某個人特定年齡的照片,但是包含同一個人不同年齡段的,樣本卻非常少。此外,年齡還存在生理年齡與外貌年齡嚴重不匹配的問題,許多人的外貌年齡要遠遠小於生理年齡,而在國際上則也有相反的情形。最後,在年齡數據集中,小孩和老人的數據量往往遠少於中年人的數據量。
再以表情為例,大量的表情樣本都是在非自然狀態下獲得,而在自然狀態下獲得的表情中,又以高興和中性的表情為主,其他表情非常少,樣本分布非常不均衡。
遇到這種情況時,如不作任何處理,不常見的樣本會淹沒在常見樣本中,不常見樣本中的特徵得不到充分學習,導致訓練出的模型在實際應用時效果不好。常用的解決方法有重採樣和代價敏感學習,即給予不同類別樣本不同的權重,構造新的損失函數。
除了透過損失函數的巧妙設計解決樣本不均衡的問題外,還可以透過數據預處理對數據,進行進一步擴充。Guenther et al. 提出了 Alignment-Free
Facial Attribute Classification Technique (AFFACT) 作為解決方案。
在訓練階段,人臉圖片被旋轉,縮放,裁剪,水平翻轉,另外用高斯濾波器對部分圖片進行模糊處理。在測試階段,縮放的圖片被截取成 10 張圖,包括中間圖,沿 4 個角截取的圖,以及水平翻轉後相應的 5 張圖。最終模型預測結果,是在 10 張圖上預測結果的平均值。AFFACT 有效的提高了網路模型的性能。
另外,隨著人臉屬性編輯模型性能的不斷提升,相信未來也會用這種方法人為創造出更多新的數據。甚至可能人臉屬性分析與人臉屬性編輯又再次合二為一,成為一個整體的模型,從不同的方向輸入,對應不同的任務。
3 人臉屬性辨識的常用骨幹網路
模型除了追求精度,隨著移動端的需求越來越大,速度也是研發人員考慮的重要因素。於是輕量級的小網路孕育而生,經典的比如 MobileNet V1/V2/V3,ShuffleNet
V1/V2 等。
3.1 ShuffleNet V2
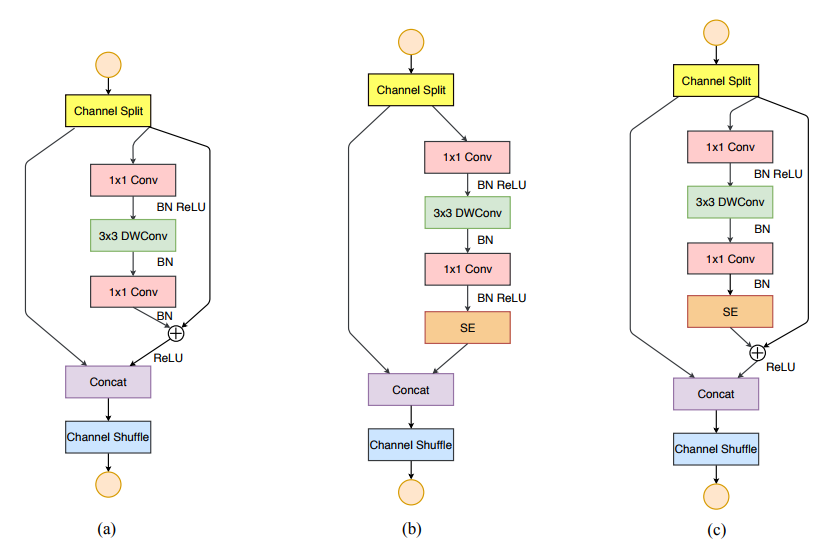
先來看一下 ShuffleNet V2,這是曠視 2018 年給出的模型。作者提到,對於速度,網路設計時不能僅僅考慮 FLOPs(floating-point operations per second,每秒浮點運算次數),由於不同設備的內建記憶體訪問耗時是不同的,模型的並行度也是不同的,更少的 FLOPs 並不代表更快的速度。不同模型比較時,要直接比較在相同硬體下(比如一塊 NVIDIA GeForce GTX 1080Ti GPU ,或一塊 Qualcomm
Snapdragon 810 ARM 板)的運行時間,而不是 FLOPs。作者在網路設計時提出了新的概念「通道切分」(channel split),將輸入分成 2 部分,最終給出的 ShuffleNet V2 的基礎模組如圖 3 所示:
2 人臉屬性辨識的難點及解決方案
人臉屬性辨識最大的困難,就在於樣本的不充分和不均衡。
以年齡為例,大量存在的樣本是某個人特定年齡的照片,但是包含同一個人不同年齡段的,樣本卻非常少。此外,年齡還存在生理年齡與外貌年齡嚴重不匹配的問題,許多人的外貌年齡要遠遠小於生理年齡,而在國際上則也有相反的情形。最後,在年齡數據集中,小孩和老人的數據量往往遠少於中年人的數據量。
再以表情為例,大量的表情樣本都是在非自然狀態下獲得,而在自然狀態下獲得的表情中,又以高興和中性的表情為主,其他表情非常少,樣本分布非常不均衡。
遇到這種情況時,如不作任何處理,不常見的樣本會淹沒在常見樣本中,不常見樣本中的特徵得不到充分學習,導致訓練出的模型在實際應用時效果不好。常用的解決方法有重採樣和代價敏感學習,即給予不同類別樣本不同的權重,構造新的損失函數。
除了透過損失函數的巧妙設計解決樣本不均衡的問題外,還可以透過數據預處理對數據,進行進一步擴充。Guenther et al. 提出了 Alignment-Free
Facial Attribute Classification Technique (AFFACT) 作為解決方案。
在訓練階段,人臉圖片被旋轉,縮放,裁剪,水平翻轉,另外用高斯濾波器對部分圖片進行模糊處理。在測試階段,縮放的圖片被截取成 10 張圖,包括中間圖,沿 4 個角截取的圖,以及水平翻轉後相應的 5 張圖。最終模型預測結果,是在 10 張圖上預測結果的平均值。AFFACT 有效的提高了網路模型的性能。
另外,隨著人臉屬性編輯模型性能的不斷提升,相信未來也會用這種方法人為創造出更多新的數據。甚至可能人臉屬性分析與人臉屬性編輯又再次合二為一,成為一個整體的模型,從不同的方向輸入,對應不同的任務。
3 人臉屬性辨識的常用骨幹網路
模型除了追求精度,隨著移動端的需求越來越大,速度也是研發人員考慮的重要因素。於是輕量級的小網路孕育而生,經典的比如 MobileNet V1/V2/V3,ShuffleNet
V1/V2 等。
3.1 ShuffleNet V2
先來看一下 ShuffleNet V2,這是曠視 2018 年給出的模型。作者提到,對於速度,網路設計時不能僅僅考慮 FLOPs(floating-point operations per second,每秒浮點運算次數),由於不同設備的內建記憶體訪問耗時是不同的,模型的並行度也是不同的,更少的 FLOPs 並不代表更快的速度。不同模型比較時,要直接比較在相同硬體下(比如一塊 NVIDIA GeForce GTX 1080Ti GPU ,或一塊 Qualcomm
Snapdragon 810 ARM 板)的運行時間,而不是 FLOPs。作者在網路設計時提出了新的概念「通道切分」(channel split),將輸入分成 2 部分,最終給出的 ShuffleNet V2 的基礎模組如圖 3 所示:
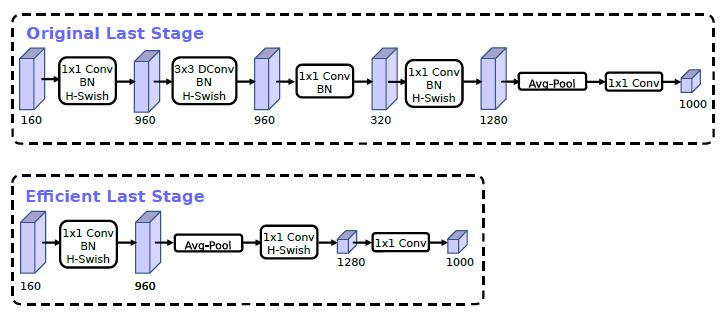
3.2 MobileNet V3
在最新的 MobileNet V3 中,谷歌的作者改進了模型的最後幾層,在不損失精度的情況下,提升了模型速度。
3.2 MobileNet V3
在最新的 MobileNet V3 中,谷歌的作者改進了模型的最後幾層,在不損失精度的情況下,提升了模型速度。
另外,作者提出了一種新的激活函數,可以有效的提升模型精度,
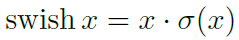
但是由於計算量過大,作者提出用下面的函數來近似,
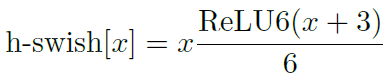
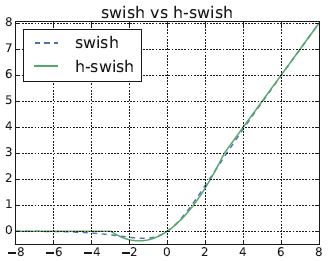
從圖 5 可以看到,h-swish 對 swish 的近似效果還是很好的。
MobileNet V3 在各個公開數據庫上,均取得了很好的效果,請有興趣的讀者朋友們閱讀原文。
4 人臉屬性編輯模型
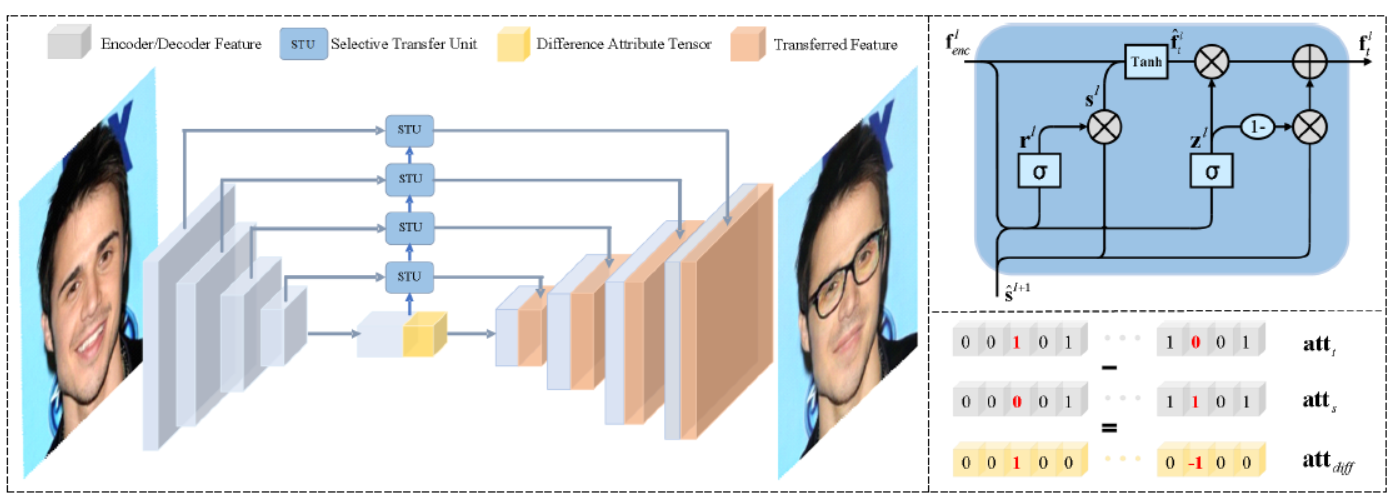
下面來看一個生成對抗網路。STGAN 指的是 Selective Transfer
GAN,是由中國的百度,於 2019 年給出人臉屬性編輯模型。原有的編輯模型很難處理高解析度程度上解決了這些問題,實現了很好的編輯效果,如圖 6 所示。

Selective 指的是 1)模型只考慮要變化的屬性,2)對於與要編輯屬性無關的區域,選擇性的拼接編碼器特徵和解碼器特徵。Transfer 指的是模型根據不同編輯任務,自適應地修改編碼器特徵。相比於用所有的目標屬性標籤作為輸入,模型選擇目標和源屬性標籤之間的差異,作為編碼器 - 解碼器的輸入,然後選擇性轉換單元(selective
transfer units)自適應地選擇,和修改編碼器特徵,並進一步與解碼器特徵連接,以達到同時增強屬性編輯能力,和提高圖像品質的目的。
下面給出模型結構:
5 中國蘇寧賣場實際應用場景
目前,在已佈署的場景中,蘇寧的人臉屬性模型還只涉及到估計。模型佈署在全國 30 多家門市店的顏值測評設備上,場景示例如圖 8:
5 中國蘇寧賣場實際應用場景
目前,在已佈署的場景中,蘇寧的人臉屬性模型還只涉及到估計。模型佈署在全國 30 多家門市店的顏值測評設備上,場景示例如圖 8:

模型可以輸出 6 個屬性,分別為性別、是否戴眼鏡、年齡、顏值、表情和歡樂度。其中,表情有 7 種,包括生氣、厭惡、恐懼、高興、中性、悲傷、驚訝,而歡樂度是基於表情裡高興的機率。
蘇寧人臉屬性 Caffe 模型 3.9 兆,模型轉換後佈署到安卓開發板上,在 RK3399 晶片上 SDK 介面調用平均耗時不到 25 毫秒。
測試集由實際場景 7500 張圖片組成,由於在 6 個屬性裡,只有性別和眼鏡有明確真值,我們對比了一下這 2 個屬性蘇寧與其他 3 家知名人工智慧公司的表現,結果見下表:
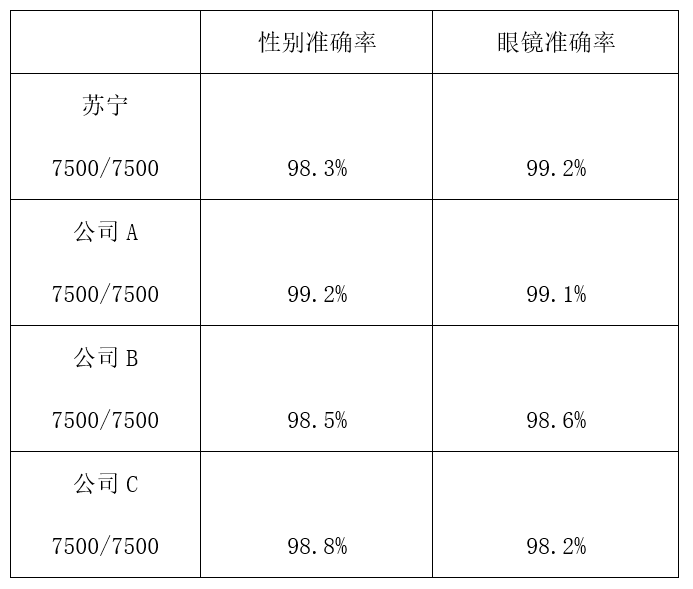
從上表可以看到,我們的眼鏡辨識的準確率是最高的,而性別辨識準確率略低於其他 3 家公司,總體性能達到了業內一流水平。
下面來看模型的顏值性能,顏值分數位於圖片下方:

從模型返回的顏值來看,分數似乎有些偏低了,尤其是某完全無名程序猿不應該僅僅比某著名演員高 2 分。
接下來看模型的歡樂度性能,歡樂度分數位於圖片下方:

從左到右三張圖,模型給出的歡樂度很好的反應了女神快樂程度的變化。
6 總結
現在我們的模型還有很多待改進的地方,比如還不能很好的區分普通眼鏡和太陽鏡;表情分類還不夠準確;對小孩和老人的年齡預測也有很大的提升空間;模型對非正臉的適應性不是很好等等。這些都是我們未來改進的方向。
當然除了現有功能的改進,也會加入新的功能。檢測表情微動作;結合關鍵點定位,可以做人臉美顏特效化妝;合成臉,如用男女朋友的臉合成未來孩子的臉等等有意思的產品。未來應用場景也不僅僅是顏值互動,比如可用於客戶分析,進行精準廣告投放等。
人臉屬性作為電腦視覺的重要分支,相信未來一定會應用在越來越多的實際場景中。
 |
沒有留言:
張貼留言