Vehicle License Plate Recognition
 |
|
任何顏色車牌——都拍攝的清清楚楚!
|
SwEn-丁
車牌辨識是以圖像分割和圖像辨識理論,對含有車牌辨識車輛號牌的圖像,進行分析處理,從而確定牌照在圖像中的位置,並進一步提取和辨識出文本字符。
車牌辨識過程包括圖像採集、預處理、車牌定位、字符分割、字符辨識、結果輸出等一系列算法運算,其運行流程如下圖所示:
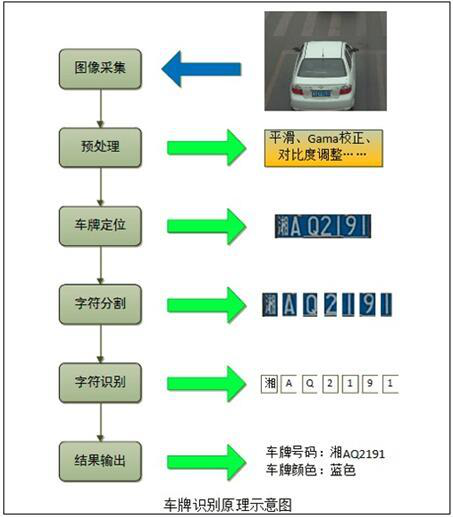
1.圖像採集
根據車輛檢測方式的不同,圖像採集一般分為兩種,一種是靜態模式下的圖像採集,透過車輛觸發地感線圈、紅外線或雷達等裝置,給攝影機一個觸發信號,攝影機在接收到觸發信號後,會拍攝一張圖像,該方法的優點是觸發率高,性能穩定,缺點是需要切割地面鋪設線圈,施工量大;
另一種是影像模式下的圖像採集,外部不需要任何觸發信號,攝影機會即時地記錄影像流圖像,該方法的優點是施工方便,不需要切割地面鋪設線圈,也不需要安裝車檢器等零組件,但其缺點也十分顯著,由於算法的極限,該方案的觸發率與辨識率較之外設觸發都要低一些。
2.預處理
由於圖像品質容易受光照、天氣、攝影機位置等因素的影響,所以在辨識車牌之前,需要先對攝影機和圖像做一些預處理,以保證得到車牌最清晰的圖像。
一般會根據對現場環境,和已經拍攝到的圖像的分析得出結論,實現攝影機的自動曝光處理、自動白平衡處理、自動逆光處理、自動過爆處理等,並對圖像進行噪聲過濾、對比度增強、圖像縮放等處理。
去噪方法有均值濾波、中值濾波和高斯濾波等;增強對比度的方法有對比度線性拉伸、直方圖均衡和同態濾波器等;圖像縮放的主要方法有最近鄰插值法、雙線性插值法和立方卷積插值等。
逆光圖像

過曝圖像

有噪聲圖像

3.車牌定位
從整個圖像中準確地檢測出車牌區域,是車牌辨識過程的一個重要步驟,如果定位失敗或定位不完整,會直接導致最終辨識失敗。車牌定位方法一般會依據紋理特徵、顏色特徵和形狀特徵等資訊,採用投影分析、連通場域分析、機器學習等算法檢測車牌。
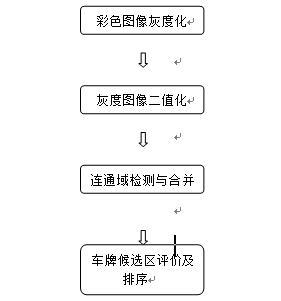
投影分析方法根據車牌字符與背景,交替出現的次數,相比於其他情況要多這個特徵,透過圖像在水平和垂直方向的投影分析,來定位車牌。連通場域分析根據車牌中的每個字符,都是一個連通場域,且這些連通場域的結構和顏色都一致的特徵,透過檢測並合併這些連通場域來定位車牌;
機器學習的思路是,先使用從很多個車牌樣本中,提取出來的特徵,把一個弱分類器訓練成一個強分類器,再使用這個強分類器,對圖像進行掃描檢測,從而定位到車牌。由於複雜的圖像背景,且要考慮不清晰車牌的定位,所以很容易把柵欄,廣告牌等噪聲當成車牌,所以如何排除這些偽車牌,也是車牌定位的一個難點。為了提高定位的準確率和提高辨識速度,一般的車牌辨識系統,都會設計一個外部接口,讓用戶自己根據現場環境,設置不同的辨識區域。
基於連通場域分析的車牌定位方法流程圖
4.車牌校正
由於受拍攝角度、鏡頭等因素的影響,圖像中的車牌存在水平傾斜、垂直傾斜,或梯形畸變等變形,這給後續的辨識處理帶來了困難。如果在定位到車牌後,先進行車牌校正處理,這樣做有利於去除車牌邊框等噪聲,更有利於字符辨識。
目前常用校正方法有:Hough 變換法,透過檢測車牌上下、左右邊框直線來計算傾斜角度;
旋轉投影法,透過按不同角度,將圖像在水平軸上進行垂直投影,其投影值為 0 的點數之和最大時的角度即為垂直傾斜角度,水平角度的計算方法與其相似;
主成分分析法,根據車牌背景與字符交界處的顏色,具有固定搭配這一特徵、求出顏色對特徵點的主成分方向,即為車牌的水平傾斜角度;
方差最小法,根據字符在垂直方向投影點的座標方差最小,導出垂直傾斜角的閉合表達式,從而確定垂直傾斜角度;透視變換,利用檢測到的車牌的四個頂點,經過相關矩陣變換後,實現車牌的畸變校正。
水平和垂直傾斜
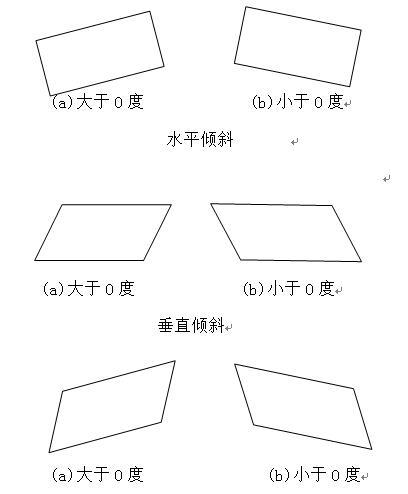
梯形畸變

5.字符分割
定位出車牌區域後,由於並不知道車牌中總共有幾個字符、字符間的位置關係、每個字符的寬高等資訊,所以,為了保證車牌類型匹配和字符辨識正確,字符分割是必不可少的一步。
字符分割的主要思路是,基於車牌的二值化結果或邊緣提取結果,利用字符的結構特徵、字符間的相似性、字符間間隔等資訊,一方面把單個字符分別提取出來,也包括粘連和斷裂字符等特殊情況的處理;
另一方面把寬、高相似的字符歸為一類從而去除車牌邊框以及一些小的噪聲。一般採用的算法有:連通區域分析、投影分析,字符聚類和模板匹配等。污損車牌和光照不均,造成的模糊車牌,仍是字符分割算法所面對的挑戰,有待更好的算法出現,並解決以上問題。

6.字符辨識
對分割後的字符的灰度圖像,進行歸一化處理,特徵提取,然後經過機器學習,或與字符數據庫模板進行匹配,最後選取匹配度最高的結果,作為辨識結果。目前比較流行的字符辨識算法有:模板匹配法、人工神經網路法、支持向量機法,和 Adaboost 分類法等。
模板匹配法的優點,是辨識速度快、方法簡單,缺點是對斷裂、污損等情況的處理有一些困難;人工神經網路法學習能力強、適應性強、分類能力強但比較耗時;
支持向量機法對於未見過的測試樣本,具有更好的辨識能力,且需要較少的訓練樣本;Adaboost 分類法能側重於比較重要的訓練數據,辨識速度快、即時性較高。
台灣車牌由英文字母和阿拉伯數字兩種字符組成,且具有統一的樣式,這也是辨識過程的方便之處。
但由於車牌很容易受外在環境的影響,出現模糊、斷裂、污損字符的情況,如何提高這類字符和易混淆字符的辨識率,也是字符辨識的難點之一。易混淆字符包括:0與D、0與Q、2與Z、8與B、5與S、6與G、4與 A 等。
污損車牌

7.車牌結果輸出
將車牌辨識結果以文本格式輸出,包括車牌號,車牌顏色,車牌類型等。
車牌輸出結果


沒有留言:
張貼留言