DeepFace -
Facial Recognition Algorithm - Facebook
 |
在上一篇文章中,我們回顧了人臉辨識算法的發展歷程,介紹了人臉辨識算法,從傳統機器學習算法,到現在的深度學習算法的演進歷程。接下來,我們將詳細介紹一下人臉辨識常見的應用方式,以及現在主流的人臉辨識算法。
1. 人臉辨識的主要應用方式
為了講清楚人臉辨識算法的設計思路,有必要首先介紹人臉辨識在實際場景中的,主要的三種不同的應用方式。這三種方式我們會習慣的稱之為:「1:1」、「1:N」,「1:n」。
1.1 驗證場景
在驗證場景下,人臉辨識算法主要用於回答「這是否為某人」。
用於回答「這是否為某人」時,該人的身份是確定,人臉辨識需要做的工作,是確認當前的照片,是否與該人的身份一致。此時會將給定的人臉圖像與電腦中,儲存的某人的圖像比較,回答給定的圖像是否為該人的。
通常,一個人在電腦中會儲存一幅正面,或多幅不同角度的圖像,我們稱之為註冊照。而給定的人臉圖像我們一般稱之為驗證照。
這種應用模式適用於門禁、出入境通關、網路實名制、辦證機構等應用場所,透過證件資訊獲取某人身份,然後根據證件使用者的照片,保證他與證件所有者是同一個人,即實名認證下的人證合一。
因為驗證場景下,通常是直接比較兩幅人臉圖像,提取出來的兩個特徵的相似度,所以我們常稱之為 1:1。

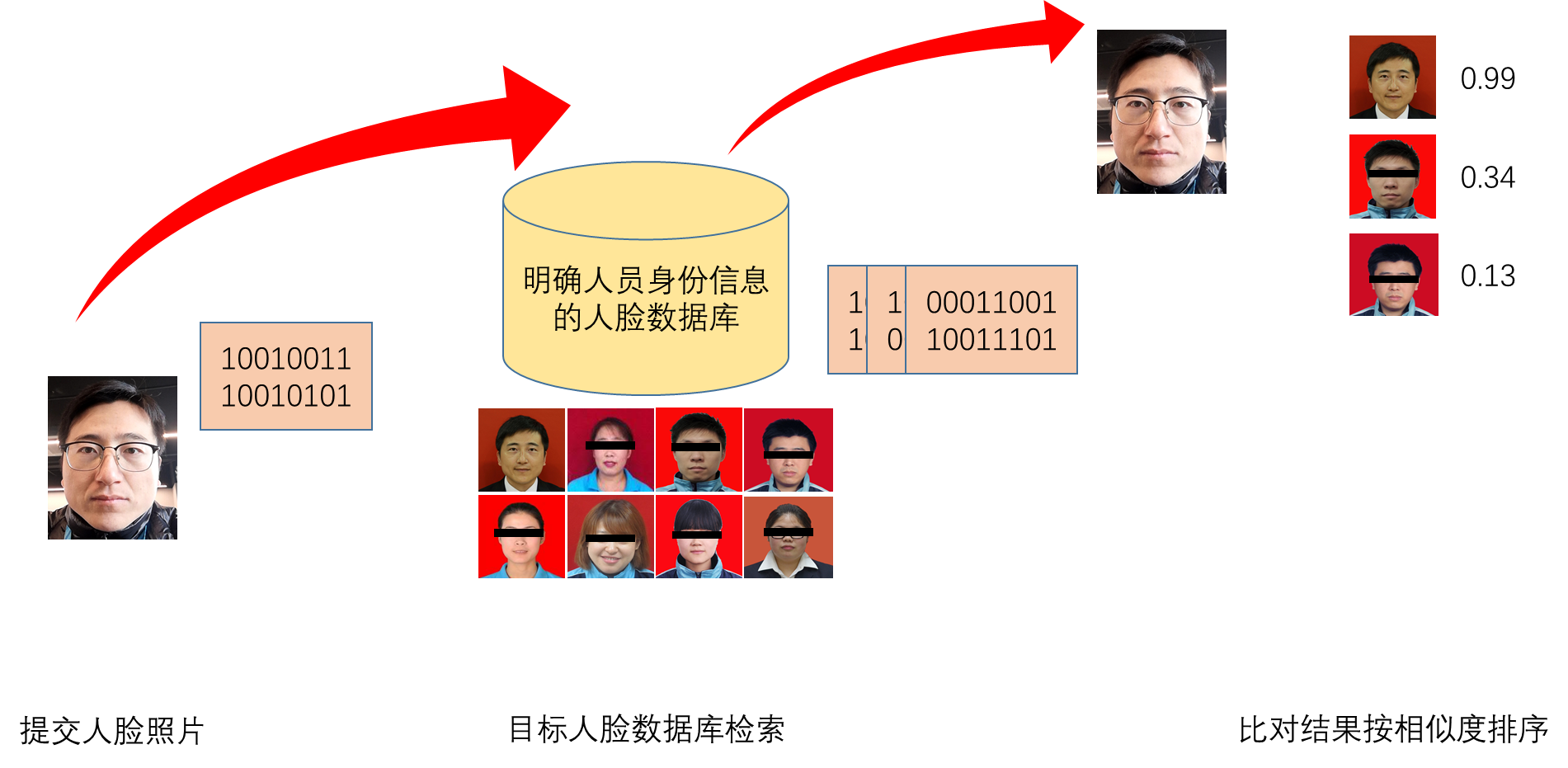
1.2 辨認場景
在辨認場景下,人臉辨識算法主要回答「這是誰」。
在這種場景下,人員的身份資訊是未知的。我們需要將給定的人臉圖像,與電腦中儲存的 N 個人的圖像逐個比對,輸出 M 幅圖像,這些圖像的相似度按從大到小排列,再由人來確定這是誰。當然,因為現在人臉辨識算法的精度非常高,所以在一些不太嚴謹的場合,可以直接用相似度最大的那張圖像,來自動判定這是誰。
通常,一個人在電腦中,會儲存一幅正面,或多幅不同角度的圖像。為了提高辨認的速度,註冊照往往會預先提取特徵,並將之儲存在電腦中。而給定的人臉圖像,我們稱之為查詢照。
這種應用模式,適用於人員身份的查詢和核查,比對目標庫通常是常住人口庫、逃犯庫等覆蓋面非常廣泛,容量非常龐大的人臉數據庫,庫容量 N 通常能夠達到上千萬、甚至上億級別。
因為辨認場景下,通常需要將給定的一副人臉圖像,與電腦中儲存的 N 個人的圖像比較,所以我們常稱之為 1:N。
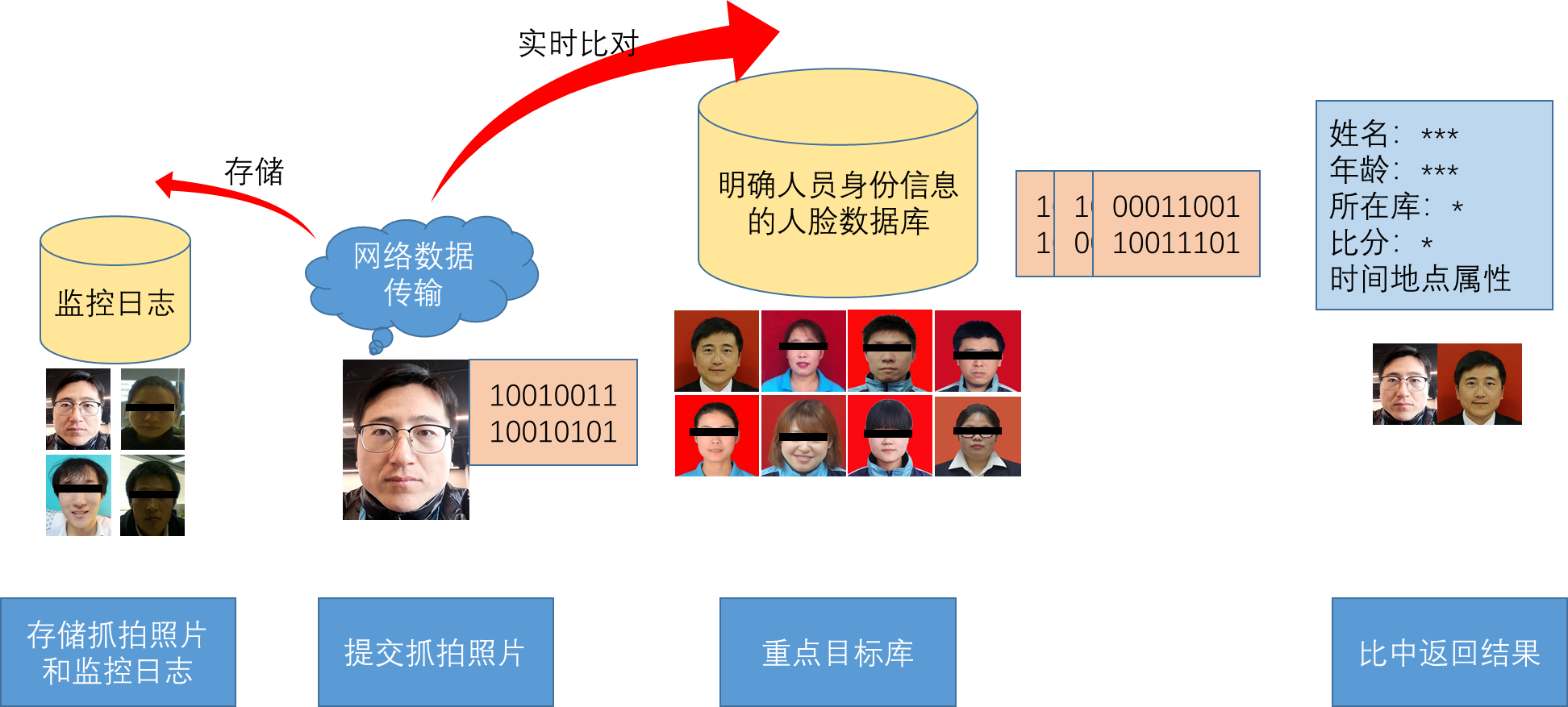
1.3 監控場景
監控場景從名字上來看就知道,人臉辨識是用於監控 (watch list) 系統(目標人篩查)。而監控場景同時具有辨認和驗證的特點,人臉辨識算法需要回答「這是否為要找的人」。
在這種情況下,人員的身份資訊同樣是未知的。我們需要將給定的人的圖像,與監控目標人員進行比較,確定該人是否在監控列表中,同時確定該人身份。
為什麼說它同時具有辨認和驗證的特點呢?是因為它需要搜索整個監控列表,這與辨認場景是類似的;同時他需要確定該人是否在監控列表中,如果將監控列表看作 1:1 中的 1 的話,這又類似於驗證場景。
但是它又完全不同於辨認或者驗證。驗證場景與它的差異很明顯,我們就不說了。而它與辨認場景的差異主要在於以下幾點:
(1)在辨認場景下,給定的人雖然身份信息未知,但是他肯定存在一張(或多張)註冊照存儲在計算機中;
(2)辨認場景下可以有人工進行參與;
(3)監控列表的容量,通常遠遠小於辨認場景下的人臉數據庫的容量。
這種應用模式適用於視頻監控,比對目標一般是逃犯、管控人員或者恐怖分子、重點關注人員等佈控人員,也可是白名單和紅名單等目標人員,庫容量一般為幾千人,甚至萬人級別。
因為監控場景下,庫容量相對辨認場景要小,所以我們稱之為 1:n。
1.3 監控場景
監控場景從名字上來看就知道,人臉辨識是用於監控 (watch list) 系統(目標人篩查)。而監控場景同時具有辨認和驗證的特點,人臉辨識算法需要回答「這是否為要找的人」。
在這種情況下,人員的身份資訊同樣是未知的。我們需要將給定的人的圖像,與監控目標人員進行比較,確定該人是否在監控列表中,同時確定該人身份。
為什麼說它同時具有辨認和驗證的特點呢?是因為它需要搜索整個監控列表,這與辨認場景是類似的;同時他需要確定該人是否在監控列表中,如果將監控列表看作 1:1 中的 1 的話,這又類似於驗證場景。
但是它又完全不同於辨認或者驗證。驗證場景與它的差異很明顯,我們就不說了。而它與辨認場景的差異主要在於以下幾點:
(1)在辨認場景下,給定的人雖然身份信息未知,但是他肯定存在一張(或多張)註冊照存儲在計算機中;
(2)辨認場景下可以有人工進行參與;
(3)監控列表的容量,通常遠遠小於辨認場景下的人臉數據庫的容量。
這種應用模式適用於視頻監控,比對目標一般是逃犯、管控人員或者恐怖分子、重點關注人員等佈控人員,也可是白名單和紅名單等目標人員,庫容量一般為幾千人,甚至萬人級別。
因為監控場景下,庫容量相對辨認場景要小,所以我們稱之為 1:n。
2. 人臉辨識的主流算法
從人臉辨識的三種主要應用方式可以看到,比較兩張人臉的圖像,是否為同一個人,是所有應用的基礎。從這個角度來說,所有的人臉辨識應用其實都是驗證場景,而人臉辨識算法的驗證性能,是衡量該算法精度高低的最直接的指標。在數據庫已知的情況下,根據驗證性能可以推算出,該算法在三種不同場景下的精度性能。
而比較兩張人臉圖像是否為同一人,主要依靠從這兩張圖像中,分別提取到的兩個特徵的相似度高低,來進行衡量。因此人臉辨識算法的關鍵,就是透過訓練一個特徵提取模型,從人臉圖像中,得到一個具有鑒別能力的特徵,而相似度的計算,則一般採用餘弦距離。
如何更加有效的訓練出,一個能夠提取具有鑒別力特徵的模型呢?一種思路通過蒐集更多的數據去提升模型的性能(從數據上挖掘),另外一種思路透過更加有效的利用數據,去提升模型的性能(從模型上挖掘)。當然,實際情況往往是兩種思路同時採用。
2.1 從數據上提高辨識性能
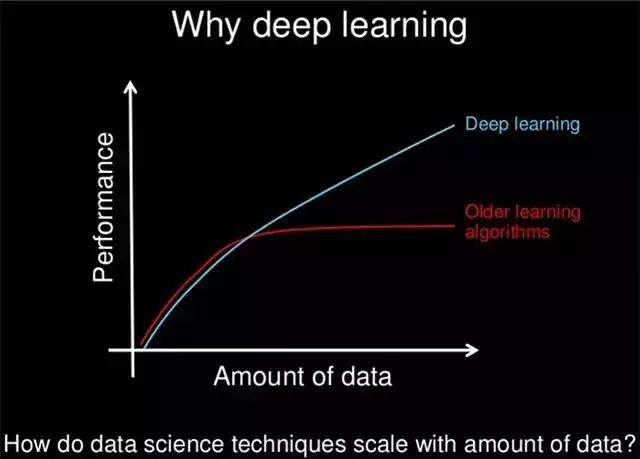
深度學習相比傳統機器學習,一個最重大的優勢,就是對海量數據的利用能力。雖然對於深度學習來說,不一定總是數據越多,效果越好,但是在人臉辨識領域,絕大多數情況是數據越多,效果越好。如果讓我選擇,我肯定會選擇要更多的數據。
在吳恩達的深度學習課程中,他曾經給出一個經典的數據,與深度學習模型性能的關係曲線。
2. 人臉辨識的主流算法
從人臉辨識的三種主要應用方式可以看到,比較兩張人臉的圖像,是否為同一個人,是所有應用的基礎。從這個角度來說,所有的人臉辨識應用其實都是驗證場景,而人臉辨識算法的驗證性能,是衡量該算法精度高低的最直接的指標。在數據庫已知的情況下,根據驗證性能可以推算出,該算法在三種不同場景下的精度性能。
而比較兩張人臉圖像是否為同一人,主要依靠從這兩張圖像中,分別提取到的兩個特徵的相似度高低,來進行衡量。因此人臉辨識算法的關鍵,就是透過訓練一個特徵提取模型,從人臉圖像中,得到一個具有鑒別能力的特徵,而相似度的計算,則一般採用餘弦距離。
如何更加有效的訓練出,一個能夠提取具有鑒別力特徵的模型呢?一種思路通過蒐集更多的數據去提升模型的性能(從數據上挖掘),另外一種思路透過更加有效的利用數據,去提升模型的性能(從模型上挖掘)。當然,實際情況往往是兩種思路同時採用。
2.1 從數據上提高辨識性能
深度學習相比傳統機器學習,一個最重大的優勢,就是對海量數據的利用能力。雖然對於深度學習來說,不一定總是數據越多,效果越好,但是在人臉辨識領域,絕大多數情況是數據越多,效果越好。如果讓我選擇,我肯定會選擇要更多的數據。
在吳恩達的深度學習課程中,他曾經給出一個經典的數據,與深度學習模型性能的關係曲線。
因此在人臉辨識行業內,大家往往會透過獲取,或者製造海量的人臉數據,去充分訓練人臉辨識模型,來獲得更好的結果。
以商湯為例,早在 2017 年的時候,他們就已經使用了多達 30 台電腦,240 個 GPU 對 10 億個標注樣本(包含 1 億個不同的人)並行訓練,總訓練時間為 1 個月左右。而現在他們的數據量的累積,到達了一個什麼程度,可想而知。
雖然數據規模,已經到達這樣一個恐怖的地步,但是人臉辨識中的數據紅利,還遠遠沒有殆盡,如何進一步從數據中,挖掘性能紅利,依然是當下人臉辨識研究的熱點之一。
因為人臉辨識應用場景的特殊性,它往往要求極低錯誤接受率下的正確辨識率,這就更是對模型的性能提出了極高的挑戰。所以可以針對不同的應用場景,如商場監控、移動辦公打卡、網路身份認證等等,採集不同場景下的大量數據,進行針對性的微調。採用這樣的方法,我們依然能夠非常有效的提升,模型在特定場景下的辨識性能。
除了獲取數據以外,業內往往還採用增加噪聲、顏色變化、隨機裁剪,或者縮放、局部區域組合、隨機遮擋等等,種種圖像變換手段,進一步產生更多的數據,以增強模型的泛化能力,防止過擬合。
2.2 從模型上提高辨識性能
數據是有限的,在有限數據的情況下,如何更加有效的利用數據,從而獲得比別人更好的性能,這就要求我們從模型上,充分挖掘已有數據的潛力,獲得更好的性能。
一般來講,業內通常有兩種做法,一種是使用更好的骨幹網路,一種是利用測度學習的手段,對提取的特徵進行優化。
2.2.1 骨幹網路設計上提高性能
1)殘差結構
在 2016 年以前,大家的主要研究方向,集中在如何設計更高效的網路去辨識人臉。在這段期間出現了如 VGG、Inception 等一系列從骨幹網路入手,去提升模型性能的算法。但是到了 2016 年,殘差網路的問世,幾乎可以說是終結了,各種千奇百怪的骨幹網路設計,順便從事實上終結了 image net 比賽。
後續幾乎所有的深度網路,都離不開殘差結構的身影,相比較之前的幾層,幾十層的深度網路,在殘差網路面前都不值一提,殘差結構可以很輕鬆的構建幾百層,一千多層的網路而不用擔心梯度消失過快的問題,原因就在於殘差結構的捷徑(shortcut)部分。
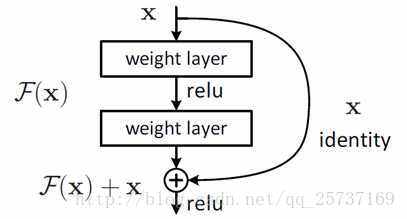
在殘差結構出現以前,影響深度學習,特別是深層神經網路訓練的,一個最主要的因素,是由於反向傳播算法的鏈式法則,導致的梯度消失和梯度爆炸,其中往往是梯度消失出現的更多一些。
透過加權正則化或梯度剪切,可以在一定程度上解決梯度爆炸的問題。
而殘差結構利用捷徑,這樣一個跨層連接的機制,無損地傳播梯度,解決了深層網路訓練中的梯度消失的問題。從此,深度學習的網路,可以輕鬆到達上百乃至上千層,而不用擔心難以訓練的問題。
2)BN 層
另外一個具有重要影響力的網路結構設計,就是 BN 層的提出。現在添加 BN 層,在幾乎所有的深度學習骨幹網路設計中,都已經成為了一個標準操作,它具有加速網路收斂速度,提升訓練穩定性的效果。
BN 全名是 Batch Normalization 即批次規範化,透過規範化操作,將輸出信號規範化,保證網路的穩定性。具體的 BN 原理非常複雜,在這裡不做詳細展開。
我們需要知道的是,它透過對每一層的輸出,規範為均值和方差一致的方法,消除了網路加權參數,帶來的放大縮小的影響,進而解決梯度消失和爆炸的問題,或者可以理解為 BN 層將輸出,從飽和區拉倒了非飽和區。它帶來的優點主要有:
(1)可以放心的使用大學習率,而不用小心的調參了,較大的學習率極大的提高了學習速度;
(2)BN 本身上也是一種正則化的方式,能夠增加模型的泛化能力;
(3)BN 降低了數據之間的絕對差異,有一個去相關的性質,更多的考慮相對差異性,因此在分類任務上具有更好的效果。
3)Dropout 層
此外,在網路特徵輸出層的後面,分類器前面添加一個 Dropout 層,也是訓練人臉辨識網路的一個常規操作。
Dropout 層是 Hinton 在 2014 年,提出來的一個神器,專門用於應對神經網路的過擬合問題。它的操作非常簡單,靈感來自於繁殖中的遺傳和突變,相當於是每次訓練,每個神經元只有概率 p 來參與單次神經網路的訓練,等效於最後的輸出層,乘以一個 Mask 矩陣,該矩陣有百分比為 p 的元素被置 0,其餘為 1。有無 Dropout,最後的分類準確率,會有明顯的差異。

它唯一的缺點,就是會明顯增加訓練時間,因為引入 Dropout 之後,相當於每次只是訓練的原先網路的一個子網絡,為了達到同樣的精度,需要的訓練次數會增多。
2.2.2 測度學習
1)Deep ID
最早用測度學習的方式,來提升模型性能的嘗試,我認為應該是 Deep ID 的工作。它為了使模型提取出來的特徵更具有區分性,在訓練網路的結構設計上,採用了類似 Contrastive Loss(對比損失)這樣的思路。

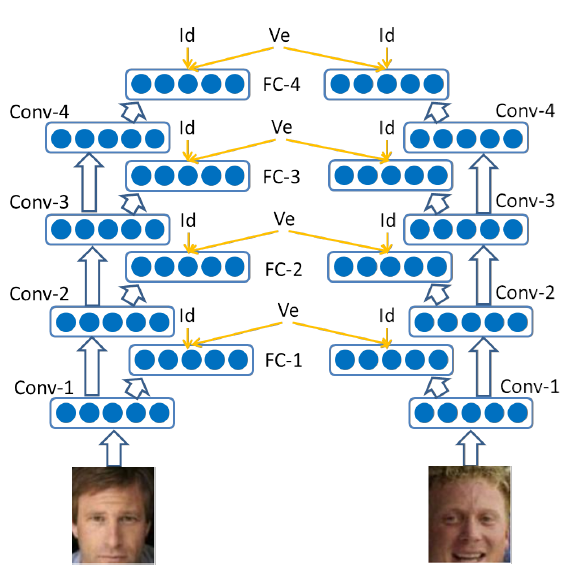
透過在 Softmaxloss 的基礎上,添加驗證信號,並與辨識信號加權,有效的提升了特徵的鑒別能力,在一定程度上縮小了類內差異,增大了類間差異。
然而 Deep ID 訓練的時候需要大量的數據,而且對比損失本身也不是很好訓練,需要小心調參才能獲得很好的結果。
2)三元組損失
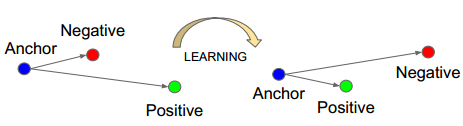
伴隨著 Deep ID 的嘗試,接下來就是谷歌的 Triplet Loss(三元組損失)。三元組損失在物理意義上,就是透過學習,使得同類樣本的 Positive 樣本,更靠近 Anchor,而不同類的樣本 Negative 則遠離 Anchor。
它在數學表達上也直觀簡單,損失函數定義為:同類樣本的距離,減去不同類樣本的距離。縮小該損失函數,就意味著縮小同類樣本的距離,或者增大不同類樣本的距離。它的實際使用效果也非常的好,特別是用在遷移學習上面。
早期三元組損失,使用歐氏距離,但是因為人臉辨識中,常用餘弦距離,衡量特徵之間的相似程度,所以後面很快就有人使用餘弦距離,對三元組損失進行了改造。
3)Insight Face
接下來測度學習的應用,集中在對訓練過程中的分類器的改造上面。因為分類器採用的全連接形式,等效於計算餘弦距離,而餘弦距離衡量的,是不同特徵之間的夾角,但是在這種形式下, Softmax 函數並沒有直接作用在角度上面,對決策邊界的影響很小,所以導致優化 Softmax 函數,並不能保證真正縮小類內差異。
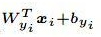
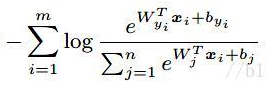
在這種情況下,就有人提出,能不能透過改造最後的分類器,使得 Softmax 函數,直接作用到角度上,從而在優化的同時,能夠保證縮小類內距離,增加類間距離。
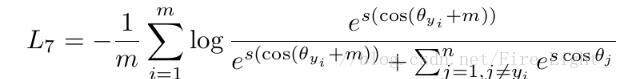
Insight Face 就在這種思想下應運而生,它的損失函數如圖 12 所示,直接作用在了角度距離上,能夠更加有效的從角度,來優化最後的決策邊界,使得同一類樣本提取到的特徵更加聚合。參數 m 則保證了不同類樣本之間的特徵,存在一定的間隔。
2.2.3 其他改進
除了上述的一些流行的改進以外,業內為了提高人臉辨識特徵,提取的精度和速度,也做了一些其它的改進。
比如最近的改進,是商湯利用深度學習,增加從側臉到正臉的映射,來提高模型的精度,即 Deep Residual EquivAriant Mapping (DREAM) 的模組。
此外還有將語音語義上,常用的注意力機制,引入到人臉辨識中的一些改進等等。
為了提高特徵提取速度,業內提出了 Mobile Face Net、Shufflenet 等輕量級網路,利用知識蒸餾的手段,去壓縮網路模型結構等。
上述這些改進也都取得了非常好的效果。
3. 人臉辨識性能的評價標準
那麼,如何評價一個人臉辨識模型性能的好壞呢?這裡介紹一下人臉辨識性能常用的評價標準。
前面介紹過,評價一個人臉辨識模型性能好壞,最直接的就是它驗證性能的好壞。評價模型的驗證性能的主要指標,包括註冊失敗率,基本等同於模板提取失敗率,驗證的 ROC 曲線及等誤率值。

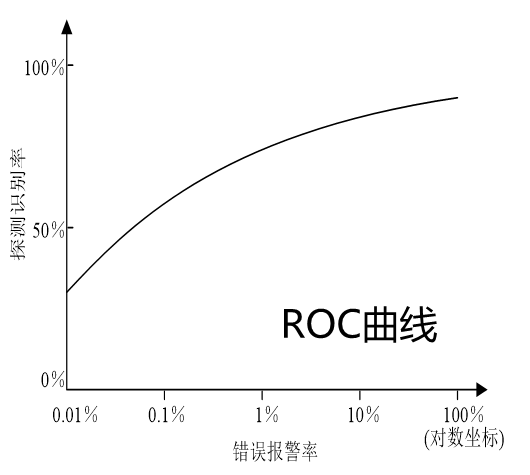
具體指標的計算如下:
(1)註冊失敗率
註冊失敗率 = 特徵提取失敗次數 / 特徵提取總次數 × 100%;
(2)錯誤拒絕率
相似度值範圍內等分為若干檔,得到若干個不同的閾值 S,計算不同閾值 S 的 FRR 如下:
FRR(S) = 同人比對相似度中低於閾值 S 的數量 / 同一人比對總數 × 100%;
(3)錯誤接受率
相似度值範圍內,等分為若干檔,得到若干個不同的閾值 S,計算不同閾值 S 的 FAR 如下:
FAR(S) = 非同人比對相似度中,不低於閾值 S 的數量 / 非同人比對總數 ×100%;
(4)等誤率
計算不同閾值時的錯誤接受率,和錯誤拒絕率。相似度閾值為橫座標,錯誤接受率和錯誤拒絕率為縱座標,用不同閾值的錯誤接受率,和錯誤拒絕率數據繪製曲線,如圖 13 所示,錯誤接受率等於錯誤拒絕率點的縱座標值,為等錯誤率。
4. 蘇寧在人臉辨識上的探索
4.1 蘇寧人臉辨識的主要用用場景
人臉辨識在蘇寧的各種應用場景下,都得到了廣泛的應用。最典型的應用,如員工打卡和蘇寧園區內部的監控,相對來說人臉數據庫的規模比較小,場景比較受控,而且人員的配合度比較高。我們的算法在這上面,都取得了非常高的辨識精度,千萬分之一 FAR 下的 FRR 在 5% 以內。
但是,對人臉辨識來說,最具有挑戰性的場景還是大規模的 1:N 的人臉應用。N 的規模通常在千萬級別或者億級別,直接從絕對數字上,放大了人臉辨識的產生的各種錯誤。這種場景通常會出現在,警政公安系統的安控場景下(這是以中國這種集權國家而言,民主世界許多國家都不允許使用人臉辨識於警政應用上),其他情況下的具體應用,還幾乎沒有。但是其實在智慧零售中也需要大規模 1:N 的人臉辨識能力。
蘇寧線下門市店人臉辨識應用的難度,又進一步增加:首先這是一個非用戶配合的場景;其次蘇寧有幾億會員,這個 N 是很恐怖的;再次,從業務上希望能夠對用戶進行分組,能夠去除店員的資訊,辨識出 VIP 會員,還要能對新用戶進行挖掘,同時要能做到黑名單的安全佈控;除此之外,有幾千家門市店的數據推流,系統的流量也是很大的。要設計這樣的解決方案,是非常恐怖的。
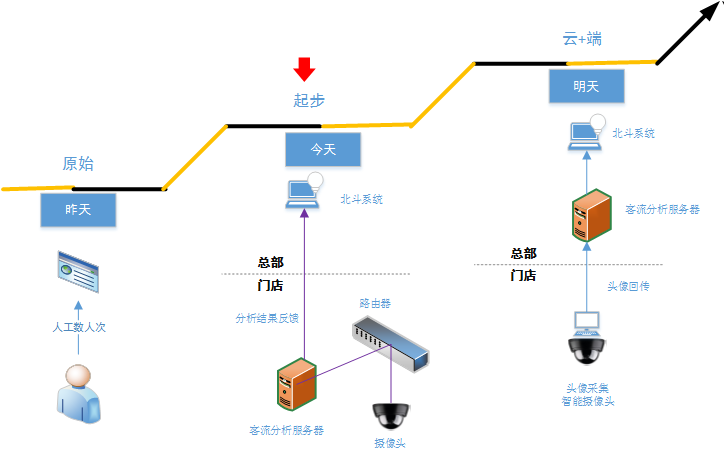
早期蘇寧的人臉辨識系統還不完善,這樣的龐大工作量幾乎完全由人工處理。但是隨著蘇寧人臉辨識算法的日益成熟,現在 AI 已經取代人,實現了完全自動化的客流分析統計、VIP 客戶辨識等功能,並應用在了蘇寧線下門市店中。

這裡我們不再過多討論,系統架構的複雜,而是接著介紹一下,蘇寧在人臉辨識上的一些實戰經驗。
4.2 數據上的探索
對於蘇寧來說,如何獲取更多更豐富的人臉數據,並進行有效清洗,也始終是工作的重點之一。有了豐富的圖像來源還不夠,因為採集到的人臉圖像,往往有很嚴重的噪聲;雖然算法模型,對一定的人臉噪聲足夠增強,但我們研究發現,更加高品質的數據集,的確可以提高算法模型性能,所以仍需要透過清洗標注,來去除這些噪聲數據。
為此,蘇寧專門成立了數據處理部門,用於獲取、清洗和標注數據。除了已知常見的那些公開數據集,如 MS_celeb_1M、VggFace2、CASIA_WebFace 等。我們也利用蘇寧多樣化的內部場景,構建了豐富的針對不同場景的人臉數據庫資源,這樣訓練出的模型,在實際場景中有更好的區分能力。
此外,我們也利用多種圖像處理手段,以及利用對抗式生成網路,生成了豐富多彩的人臉樣本,進一步提高了模型精度。
4.3 模型上的探索
蘇寧在人臉辨識算法上,尤其是模型上也做出了許多的探索。美國普渡大學生物工程學教授 Eugenio Culurciello ,在他的神經網路設計史中,給出了一張有關不同的骨幹網路,在 ImageNet 上的表現的分析圖。我們在它的基礎上,重點測試了 Resnet、Mobilenet 等幾種骨幹網路,根據速度和精度,選出了最適合我們應用場景的模型。

而在損失函數上,我們選擇了使用 InsightFace 進行預訓練,使用三元組損失針對不同的應用場景進行微調。
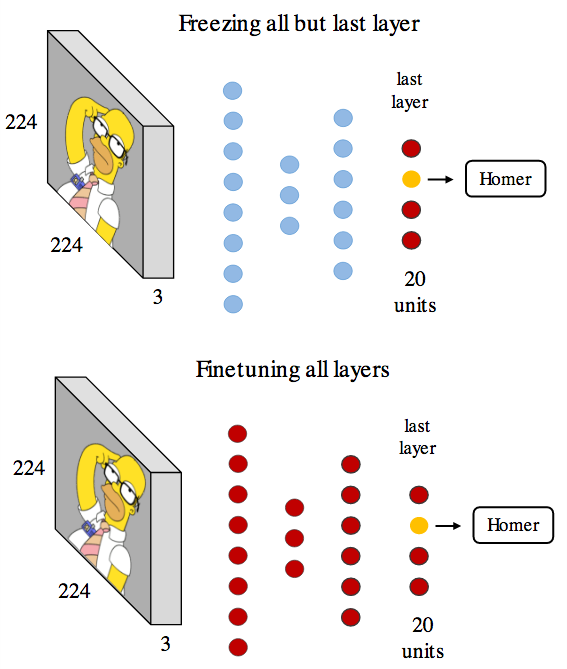
微調過程中,會首先固定所有層的參數,只微調最後一層特徵,在調整到一定程度之後,才會放開所有的參數,微調整個模型。
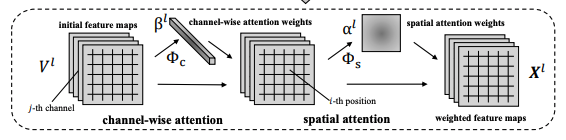
此外,我們還添加了一些注意力機制,如 SCA-CNN 中提出的空間和通道注意力機制等,使得我們的模型更多的關注有鑒別力的區域,能夠更加有效的去辨識不同身份的人臉,針對化妝、眼鏡、髮型等干擾因素,也能有很好的效果。
5. 總結
至此,我們介紹了人臉辨識在業內主要的三種應用方式,以及目前主流的算法。同時我們還介紹了蘇寧的人臉辨識在智慧零售中的主要應用,以及我們對於人臉辨識算法的一些有益探索。
但是一個完整的人臉辨識系統,並不是只有人臉辨識算法,就能夠正常的工作運行的,它還需要諸如人臉檢測、關鍵點定位等諸多算法的配合。
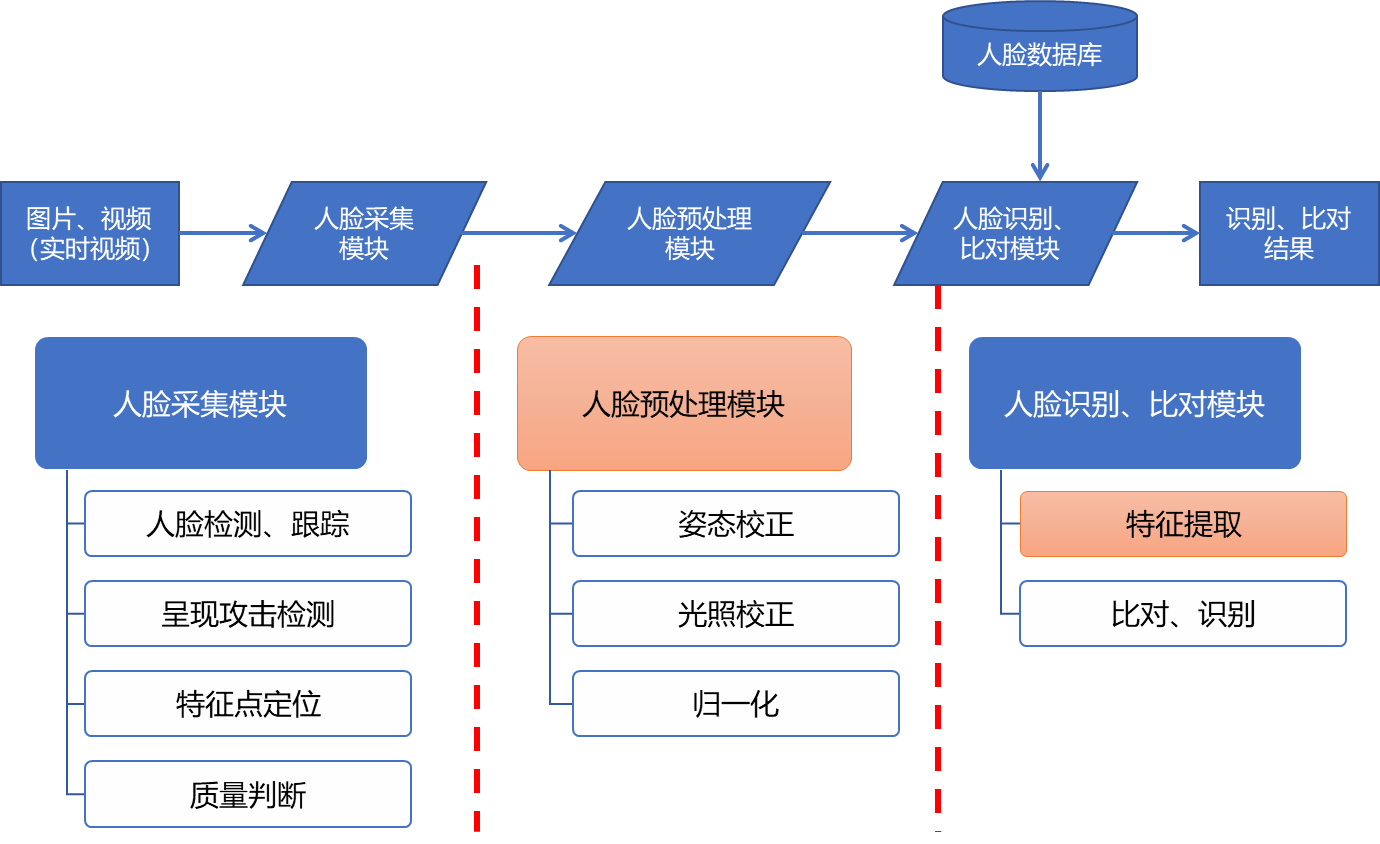
在下一篇文章,我們將拓展介紹一下這些相關的算法,以及它們在行業內的主流方法,及相關應用。
作者簡介
蘇寧科技人工智慧實驗室 圖像技術專家何智翔
畢業於對岸中國清華大學 THOCR 實驗室,師從對岸中國著名人工智慧專家 IEEE fellow 丁曉青教授,十餘年來一直從事人臉相關算法的研究。現任蘇寧科技人工智慧實驗室圖像技術專家,主要研究方向為人臉屬性的辨識、商品的檢測和辨識。


沒有留言:
張貼留言